1、情况1,加上accept-encoding会解码不出来,这时可以去掉即可。
说明,对于一些网站,有时候爬取的时候,如果headers中加入这个accept-encoding参数之后会有一些乱码返回,这个时候可以把这个参数去掉,查看是否有些正常的html格式,如果有些正常,还有些乱码,这个时候需要进行一些编码转换即可:
if-modified-since 这个参数是403错误,去掉就可以了,我之前写过一个博客,具体这里不解释了。
比如:
我加上全部参数,返回=的是乱码,然后找了测试找原因。。。。
这个时候我使用这个返回的, text = resp.text
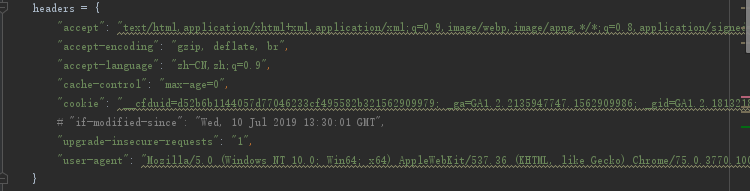
然后尝试使用resp.content.decode(“utf-8”)和gbk,都尝试无效
最后把参数注销再次尝试;
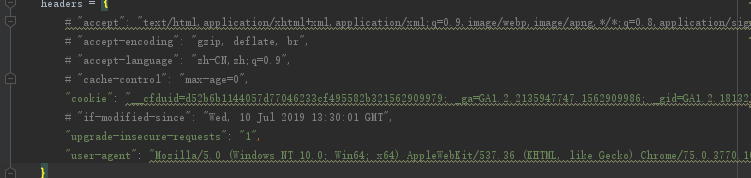
这个时候,返现html界面有了,就是中文有问题,这个时候我就知道哪里的原因了(别问我为什么,因为我经过过这种次数多了,见得多了就知道了)这个时候把
text = resp.text 改为使用resp.content.decode(“utf-8”)就可以了
到此基本结束,因为我第一次见得这种情况,所以。。。想知道为什么会刚刚那样,经验猜想告诉我,应该刚刚第一次乱码是压缩,所以,尝试测试。。。
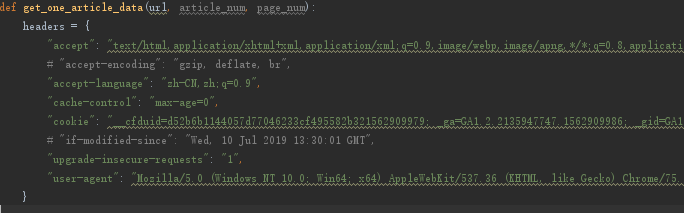

果然如此,所以,以后在遇见这个问题就知道网哪里考虑了,不用一直纠结了。

结束!!!!
2、第二种情况,也是我刚遇到这,加上这个参数会正确响应返回结果,这时候加上这个参数即可。
具体网站不方便公示,如果有人遇到爬取网站响应返回的如果是有验证码,或者乱码,可以考虑下这个参数。我也是找了很久才发现,刚开始一直以为换ip好了,发现还是响应的结果时好时坏,然后一点点找原因,基本上一下午都在找这个原因。遇到我这种情况可以考虑下这个参数吧。
“accept-encoding”: “gzip, deflate, br”
把这个参数正常就可以了。

