说明:
由于好久(半年以上了)没有用到scrapy框架做爬虫了,日常的使用request+多线程和协程就能高速爬取了,时间久了发现不怎么熟练了,抽空闲时间再复习一下,巩固。
我的工作环境:
1 | windows10系统 |
2 | python3.6 |
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
1、scrapy的爬虫流程:
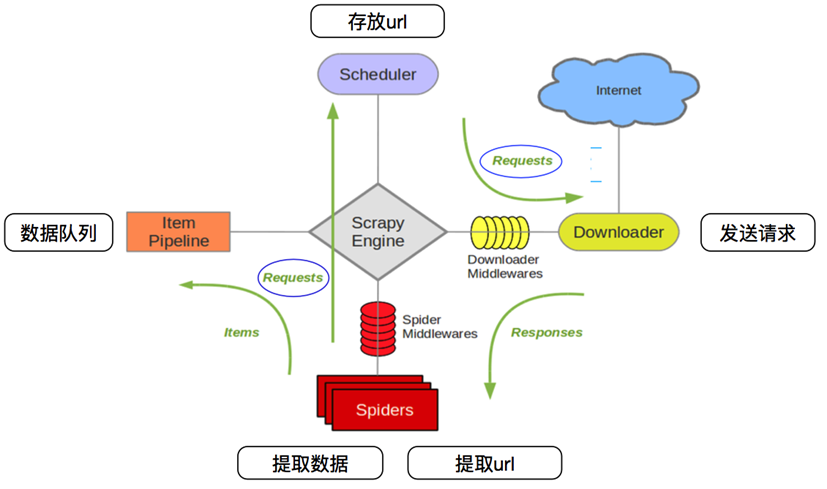 在这里插入图片描述
在这里插入图片描述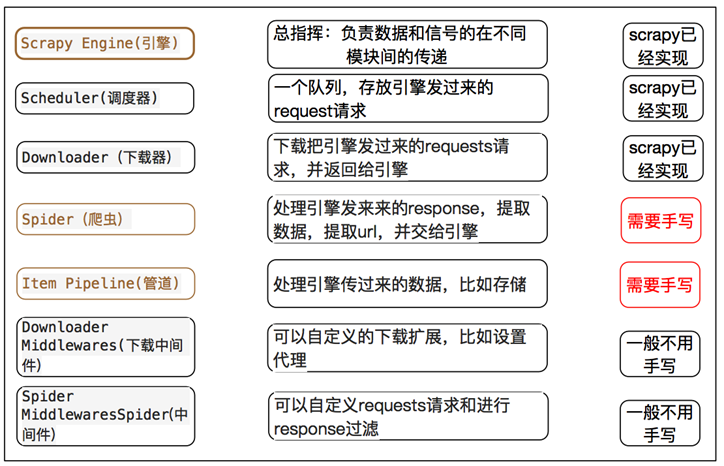 在这里插入图片描述
在这里插入图片描述
2、scrapy入门:
创建一个scrapy项目
scrapy startproject mySpider生成一个爬虫
scrapy genspider xiaohuar “xiaohuar.com”提取数据
完善spider,使用xpath等方法保存数据
pipeline中保存数据
3、几个必须掌握的全局命令:
1 | 1. scrapy startproject(创建项目) |
2 | 2. scrapy genspider demo demo.com (初始化爬虫文件) |
3 | 3. scrapy crawl XX(运行XX蜘蛛)、 |
4 | 4. scrapy shell http://www.scrapyd.cn(调试网址为http://www.scrapyd.cn的网站)-- 可以用来调试测试response含有的方法,或者xpath提取的方法,进行测试。 |
1、创建一个scrapy项目
1 | scrapy startproject mySpider |
scrapy startproject这里是固定的,注意scrapy和startproject和mySpider中间是有空格的!后面的:mySpider是我们创建的蜘蛛名字,后面我们运行的时候用得到,你需要根据你的情况创建,比如你是想爬取淘宝你可以这样创建:
1 | scrapy startproject taobao |
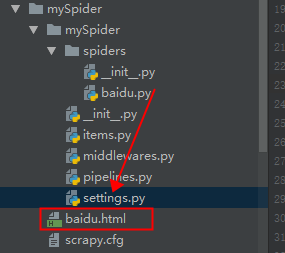
会在当前目录下生成一个test_1的目录,结构如下图
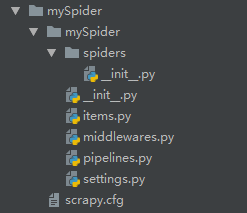
下面来简单介绍一下各个主要文件的作用:
- scrapy.cfg :项目的配置文件
- mySpider/ :项目的Python模块,将会从这里引用代码
- mySpider/items.py :项目的目标文件
- mySpider/pipelines.py :项目的管道文件
- mySpider/settings.py :项目的设置文件
- mySpider/spiders/ :存储爬虫代码目录
2、明确目标(mySpider/items.py)
我们打算抓取:http://top.baidu.com/百度风云榜实时热点前十条信息
- 打开mySpider目录下的items.py
- Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
- 接下来,创建一个BaiduItem 类,和构建item模型(model)。
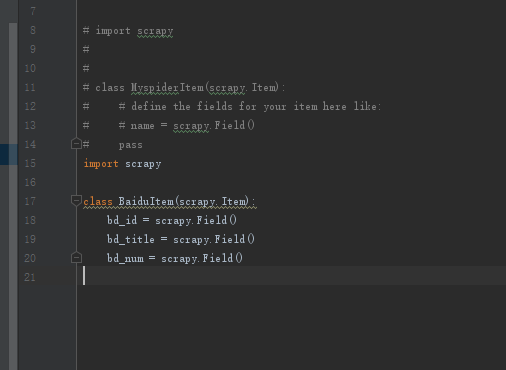
items.py 默认会是这种:
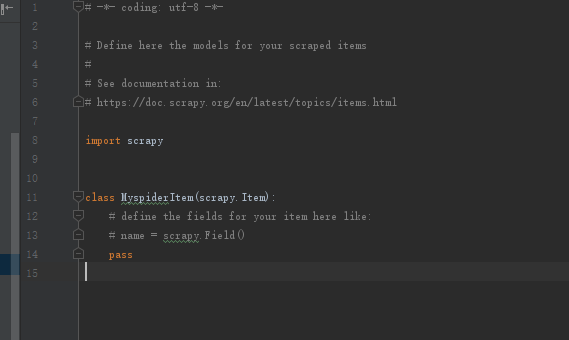
改为这个:
1 | import scrapy |
2 | |
3 | class BaiduItem(scrapy.Item): |
4 | bd_id = scrapy.Field() |
5 | bd_title = scrapy.Field() |
6 | bd_num = scrapy.Field() |
3、制作爬虫 (spiders/baidu.py)
这里主要分为俩步:爬数据+取数据

1、制作爬虫文件默认格式
1 | cd mySpider |
2 | scrapy genspider baidu "top.baidu.com/" |
然后会在spiders下面生成一个baidu.py文件,里面内容是下面的默认格式,自己再进行修改。
打开 mySpider/spider目录里的 baidu.py,默认增加了下列代码:
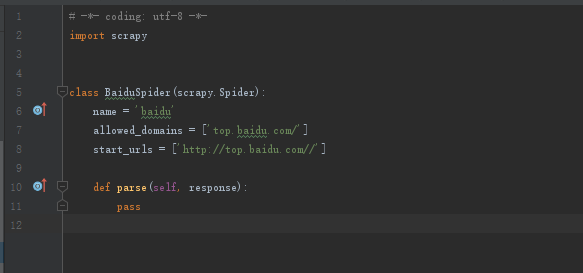
其实也可以由我们自行创建baidu.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
- name = “” :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
- allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
- start_urls = () :爬取的URL元组/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求。
如果需要将start_urls的值修改为需要爬取的第一个url,或多个url,会多线程爬取这些。
2、修改parse()方法
1 | def parse(self, response): |
2 | # pass |
3 | print("进来了") |
4 | with open('./baidu.html', 'wb') as file: |
5 | file.write(response.body) |
结果发现打印不出来“进来了”,我这里猜想是robot协议问题
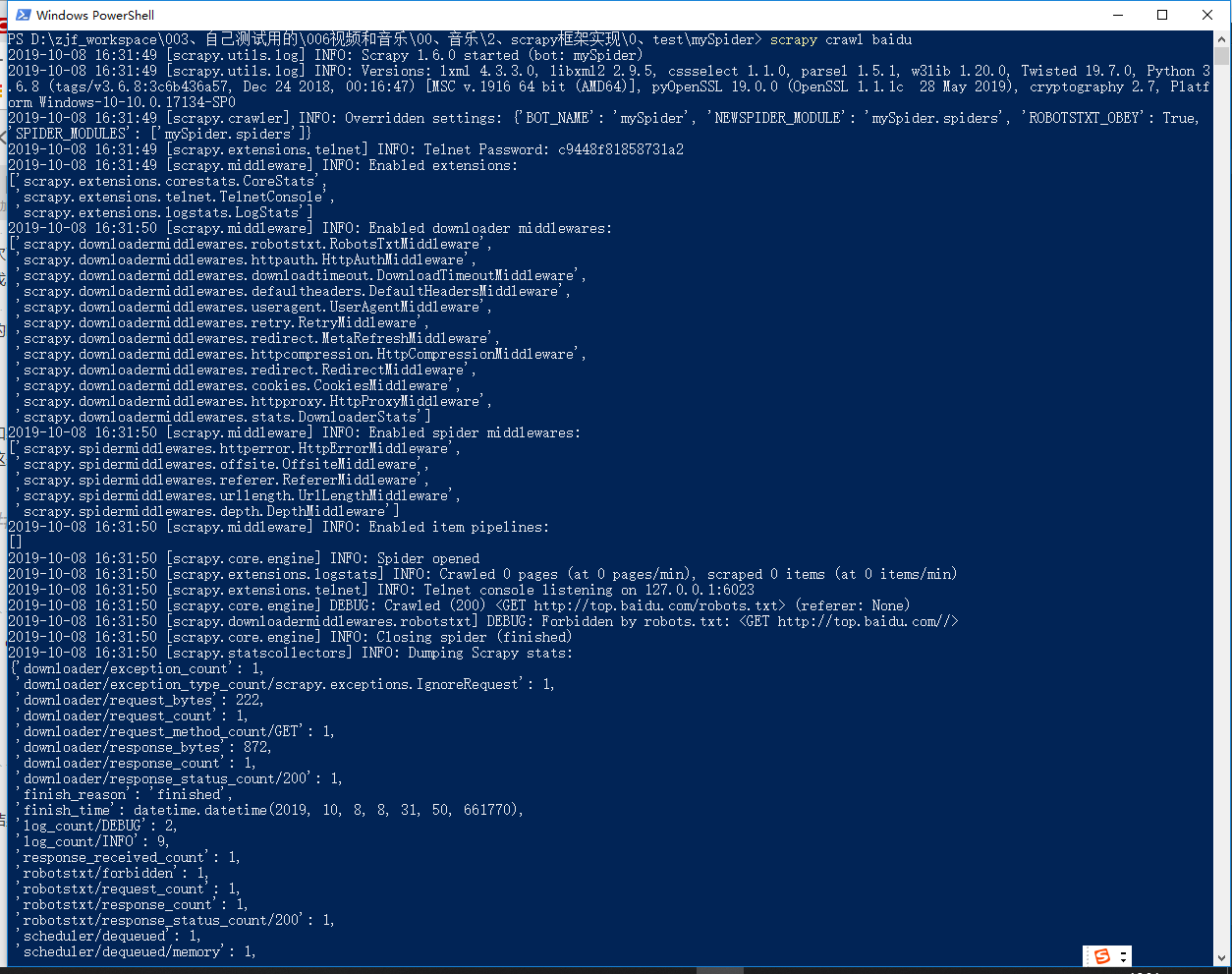
更改robot协议,为False,并且将log级别更改为:
1 | ROBOTSTXT_OBEY = False |
2 | |
3 | _LEVEL = 'DEBUG' |
4 | LOG_LEVEL = "WARNING" |
成功打印出“进来了”:

然后在项目目录下生成一个baidu.html,这个就是爬取http://top.baidu.com/返回的页面。
这个时候,我们可以提取数据了,但是我忘记之前是如何提取的了,我只记得和request返回的是不一样的,怎么办,这时候可以考虑打印出来,看看response是什么类型,有什么方法:

打印出类型和拥有的方法:

3、使用xpath提取数据:
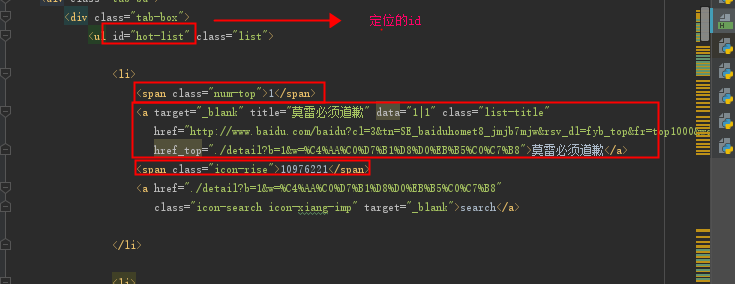
保存的页面分析:
提取代码:
1 | def parse(self, response): |
2 | # 测试是否能进来 |
3 | print("进来了") |
4 | # 保存下来响应页面 |
5 | # with open('./baidu.html', 'wb') as file: |
6 | # file.write(response.body) |
7 | # 打印出类型和方法 |
8 | # print("type_response", type(response)) |
9 | # print("dir_response", dir(response)) |
10 | # xpath提取数据 |
11 | li_list = response.xpath('//*[@id="hot-list"]//li') |
12 | items = [] |
13 | for li in li_list: |
14 | # 将我们得到的数据封装到一个 `BaiduItem` 对象 |
15 | item = BaiduItem() |
16 | # extract()方法返回的都是字符串 |
17 | # 名次 |
18 | bd_id = li.xpath('./span[@class="num-top" or @class="num-normal"]/text()').extract() |
19 | # 标题 |
20 | bd_title = li.xpath('./a[@class="list-title"]/text()').extract() |
21 | # 搜索指数 |
22 | bd_num = li.xpath('./span[@class="icon-rise" or @class="icon-fall" or @class="icon-fair"]/text()').extract() |
23 | |
24 | # xpath返回的是包含一个元素的列表 |
25 | item['bd_id'] = bd_id[0] |
26 | item['bd_title'] = bd_title[0] |
27 | item['bd_num'] = bd_num[0] |
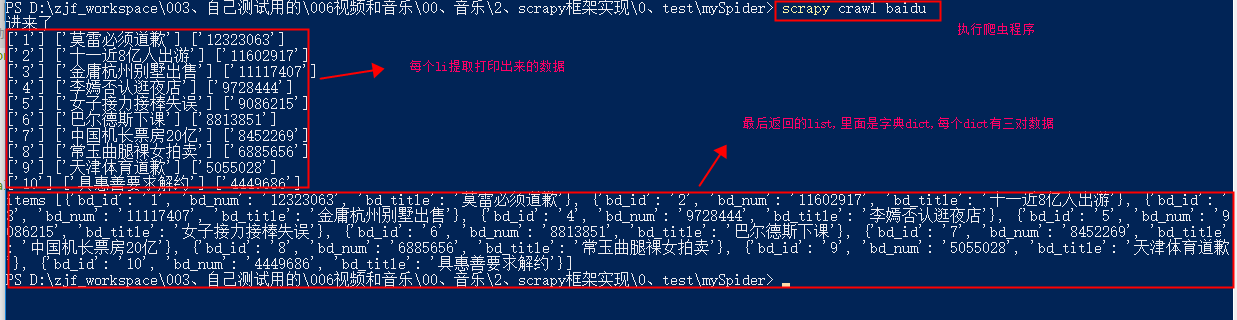
28 | print(bd_id, bd_title, bd_num) |
29 | items.append(item) |
30 | # 直接返回最后数据 |
31 | print("items",items) |
32 | return items |
注意点:
使用xpath提取字符串:
后来补充测试,截图如图: 在这里插入图片描述
在这里插入图片描述①、extract() 返回的是一个包含字符串数据的列表【和getall()方法返回的结果一样】
②、extract_first() 返回的是列表的第一个字符串【和get()方法返回的结果一样,】
response.xpath() 返回的是一个含有selector对象的列表
需要爬取的url必须在allowed_domains域名下的链接,allowed_domains里面可以存放多个域名,如果需要爬取其他地址,可以自己想需要爬取的跳转网页的域名加入allowed_domains的列表中。
打印出来的数据:
4、管道保存数据(pipelines.py)
先在pipelines.py文件中增加一句,测试内容:
发现没有进入管道pipelines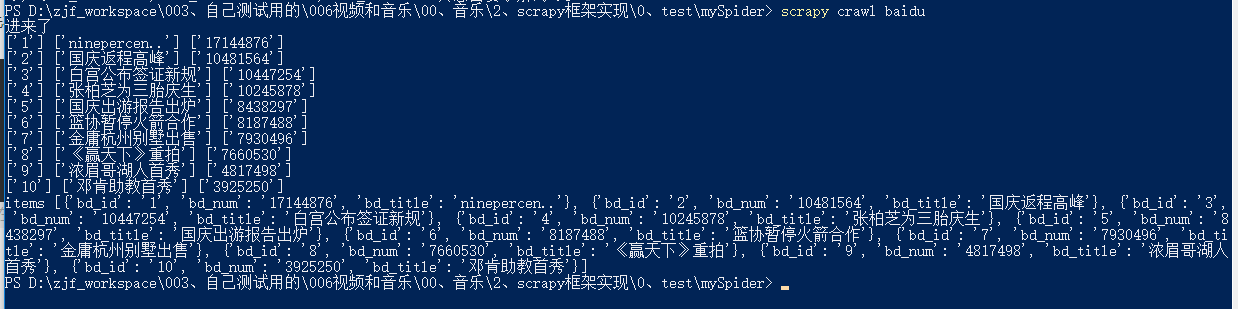
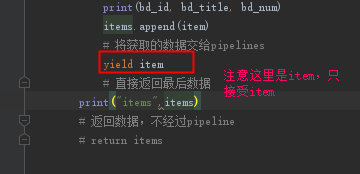
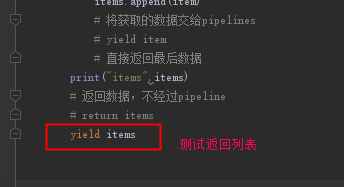
我们修改baidu.py,将return改为yield,不能对于单个dict数据返回给管道pipelines
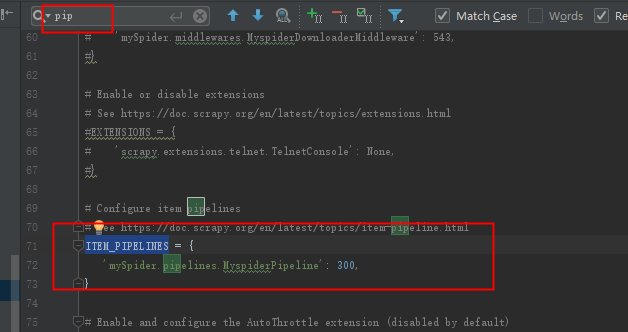
需要在setting里面把设置的管道注销的打开,这样才能进入管道。
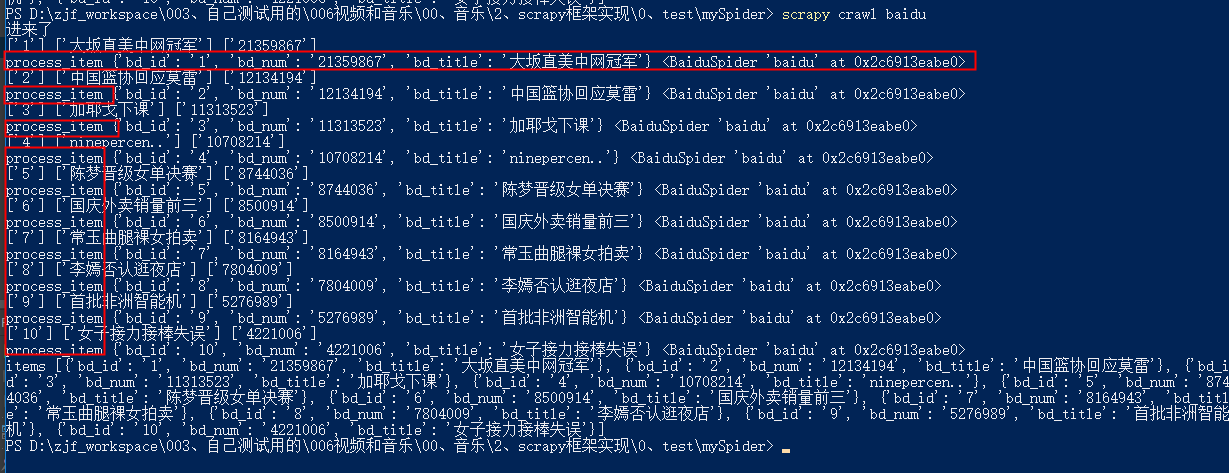
这时候就可以进入管道了。
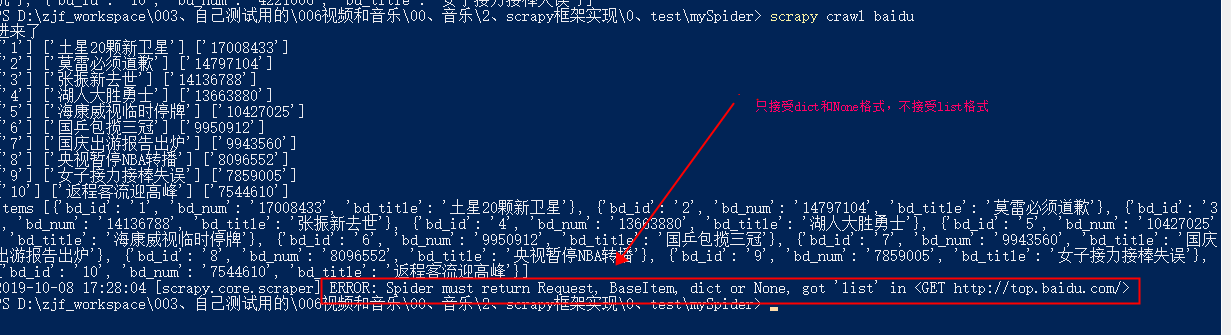
注意点:yield返回的只能是dict或者None,
yield返回进入管道的,只能是字典格式的,如果是其他的就会报错:
5、保存到MongoDB数据库:
管道代码:
1 | from pymongo import MongoClient |
2 | |
3 | |
4 | class MyspiderPipeline(object): |
5 | |
6 | def open_spider(self, spider): |
7 | print("准备创建一个数据库") |
8 | # 这个会在项目开始时第一次进入pipelines.py进入,之后不再进入 |
9 | # 建立于MongoClient 的连接: |
10 | self.client = MongoClient('localhost', 27017) |
11 | # 得到数据库 |
12 | self.db = self.client['111_test_database_baidu'] |
13 | # 得到一个集合 |
14 | self.collection = self.db['111_test_collection_baidu'] |
15 | |
16 | def close_spider(self, spider): |
17 | print('项目结束,断开数据库连接') |
18 | # 这个会在结束时开始时第一次进入pipelines.py进入,之后不再进入 |
19 | self.client.close() |
20 | |
21 | def process_item(self, item, spider): |
22 | print("process_item", item, spider) |
23 | print("type",type(item)) |
24 | # 储存到数据库 |
25 | print("准备保存到数据库") |
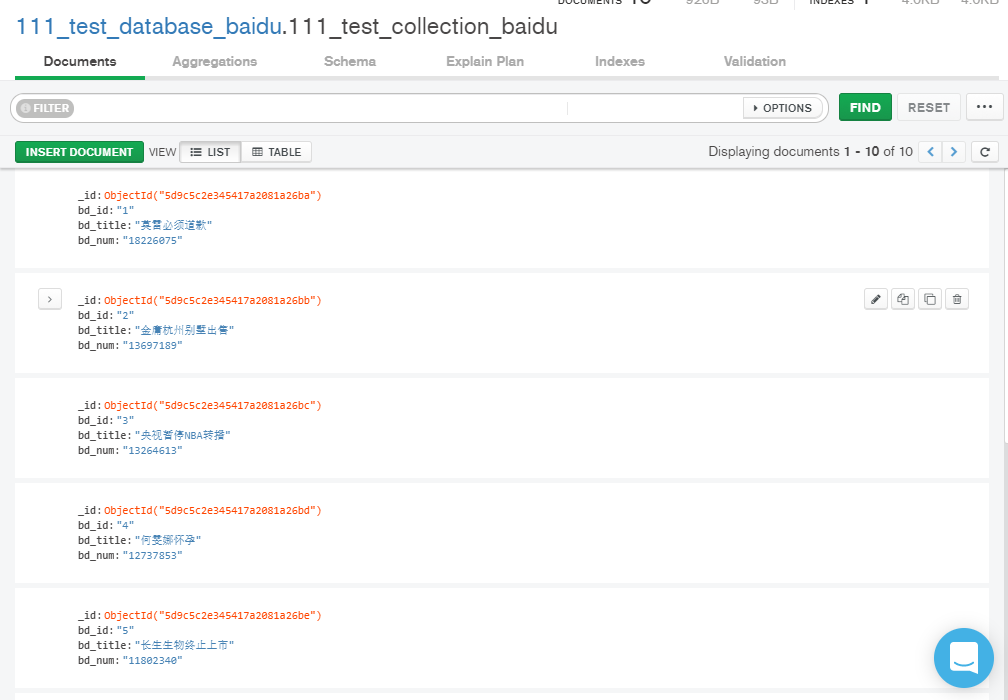
26 | self.collection.save(dict(item)) |
27 | return item |
注意点:
item看着是dict,但是还不python里面的dict,需要使用dict(item)转换一下,才能正常保存,不然报错,我这里改了就成功了:
成功报错效果图:
参考:
https://doc.scrapy.org/en/latest/topics/item-pipeline.html

