说明:
今天突然想把爬取的HTML页面转存成PDF格式,进行一个学习,起源于这个还是很久之前看到一个爬取公众号的文章保留为PDF,但是想着学习自己实现一下哈,结果(懒呀,懒人总是能找到各种借口的,一推就一俩个月过去了,今天突然就想起来了,就来实现一波,结果还真有点麻烦,代码这个还是要自己动手写写,弄好之后做个自己看懂的总结就行(因为这是你以新手的学习出发点学习的,也能帮助别人下你踩得坑),把人家写的案例自己实现或者自己模仿找个其他案例测试测试,或者多找个文章学习学习)
一、环境配置:
1、window的wkhtmltopdf下载地址
这个不按照会报一个错。
我的是window系统,所以需要还需要安装一个exe文件:
下载地址1:
下载地址2
各个平台下载的方法地址
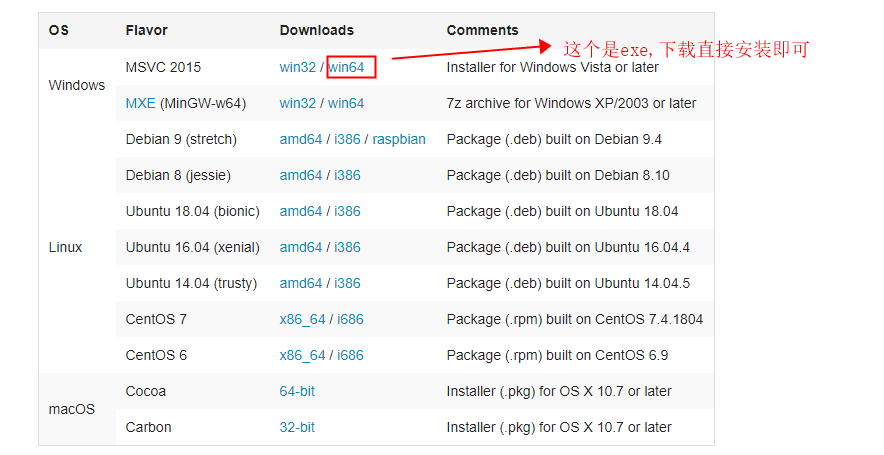
下载的exe直接安装即可,安装位置建议更改到软件盘。
==记得安装好把安装位置的bin目录放到环境变量中。==
2、安装pdfkit模块:
1 | pip install --upgrade pdfkit |
二、代码实现:
参考好几个博客之后,我找到有以下几种可以实现的方法,参考博客我放到下方,需要的可以去看看。
方法1–wkhtmltopdf命令url :
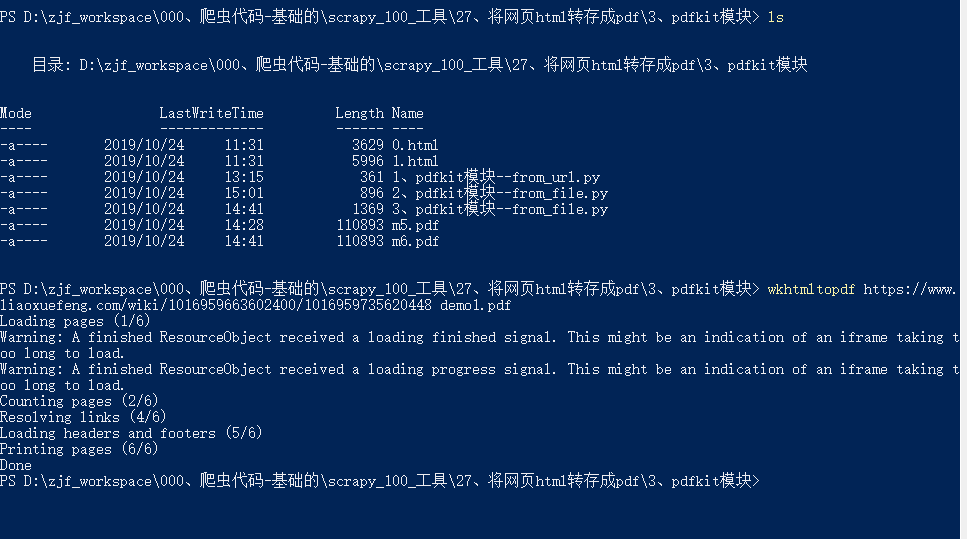
刚刚安装好,可以直接使用命令处理一个单个的url。
命令格式:wkhtmltopdf + url + 输出名称(可以是绝对路径或者相对路径)
1 | wkhtmltopdf https://www.liaoxuefeng.com/wiki/1016959663602400/1016959735620448 demo1.pdf |
方法2–wkhtmltopdf命令html:
命令格式:wkhtmltopdf + html文件 (可以是绝对路径或者相对路径)+ 输出pdf路径(可以是绝对路径或者相对路径)
1 | wkhtmltopdf .\0.html demo2.pdf |
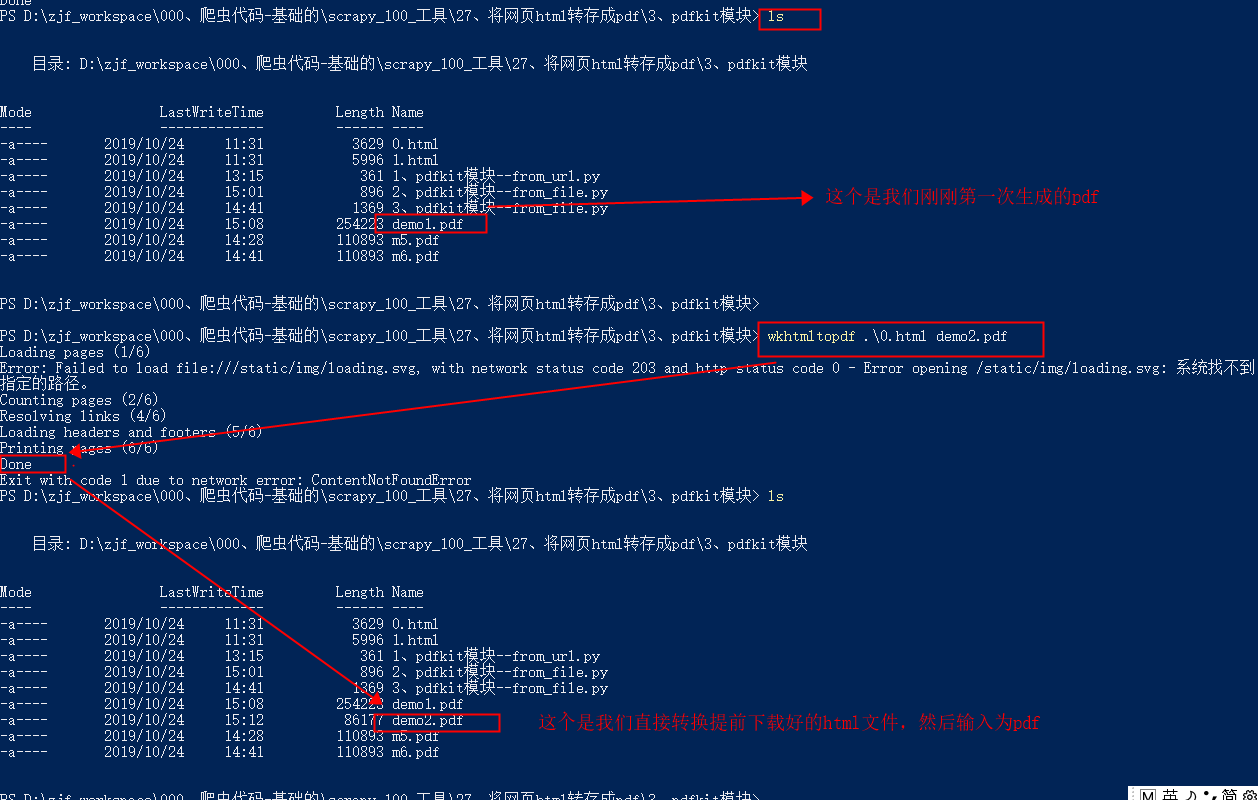
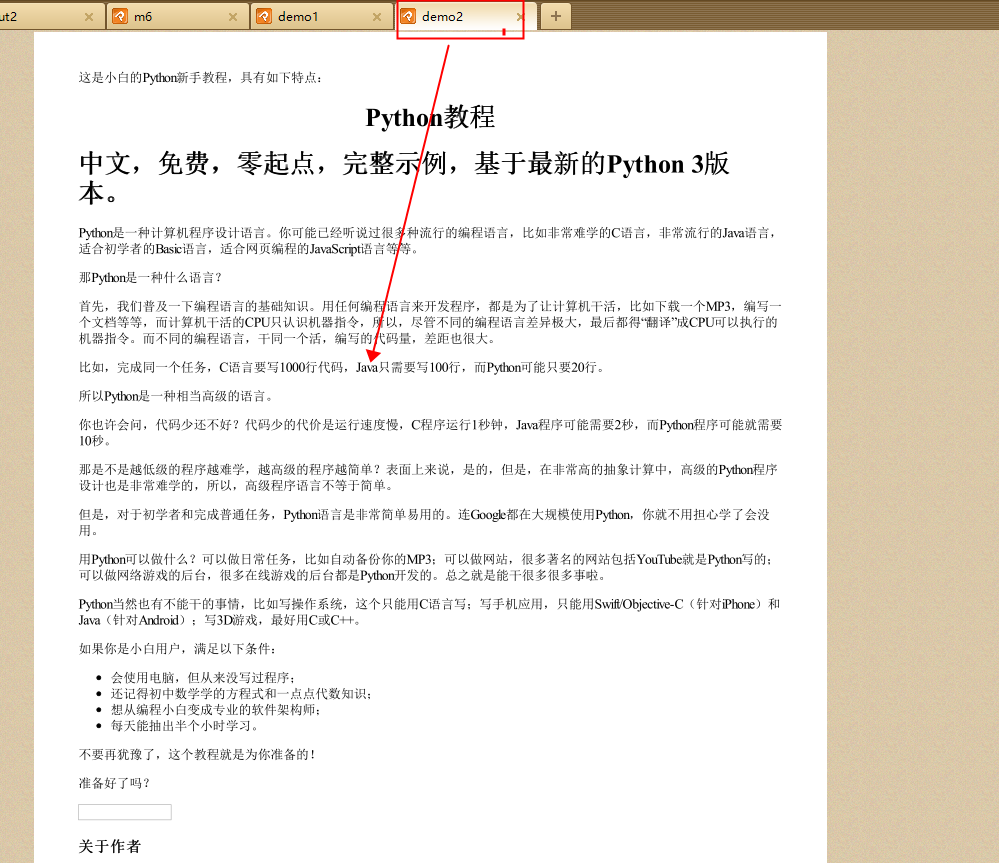
方法3–pdfkit的from_url(url这个不报错):
注意点:
这个要把刚刚安装的环境位置弄上,我添加到系统的环境变量中,不加入这个还是保错,不知道有个博主写的,他为什么可以下载保存,我这边要加上这个配置。
1 | path_wk = r'd:\tools\wkhtmltopdf\bin\wkhtmltopdf.exe' # 安装位置 |
2 | config = pdfkit.configuration(wkhtmltopdf=path_wk) |
代码演示:
1 | import pdfkit |
2 | |
3 | |
4 | path_wk = r'd:\tools\wkhtmltopdf\bin\wkhtmltopdf.exe' # 安装位置 |
5 | config = pdfkit.configuration(wkhtmltopdf=path_wk) |
6 | # pdfkit.from_url(['google.com', 'yandex.ru', 'engadget.com'], 'out1.pdf',configuration=config) |
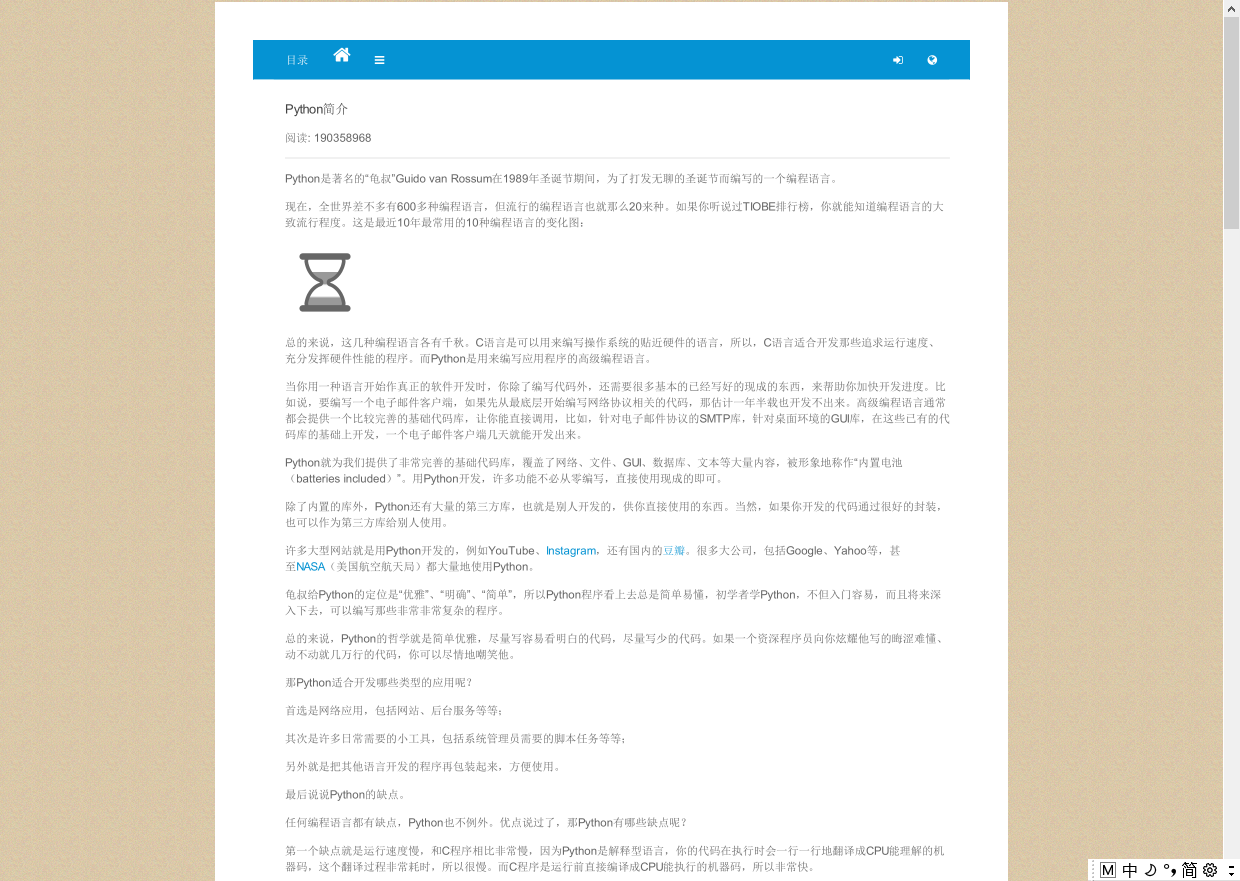
7 | pdfkit.from_url(['https://www.liaoxuefeng.com/wiki/1016959663602400/1016959735620448'], 'demo3.pdf',configuration=config) |
方法4–pdfkit的from_file(我的虽然也能成功生成pdf,但是这个会报错,找了几个小时没有找到怎么解决,如果有懂得大佬,可以赐教一下哈):
代码,可以合成单个html,也可以合成多个html:
1 | # -*- coding: utf-8 |
2 | import pdfkit |
3 | |
4 | path_wk = r'd:\tools\wkhtmltopdf\bin\wkhtmltopdf.exe' # 安装位置 |
5 | config = pdfkit.configuration(wkhtmltopdf=path_wk) |
6 | pdfkit.from_file(['0.html', '1.html'], 'demo5.pdf', configuration=config) |
能生成能打开pdf,其实效果可以了,就是报错,唯一遗憾的是一直没有找到报错解决方法,等闲了回家用自己电脑测试试试,是不是公司电脑中其他环境问题:
问题:
我把问题放到这里,如果有懂的大佬,欢迎留言给我讲解一波哈。
1 | Exception in thread Thread-2: |
2 | Traceback (most recent call last): |
3 | File "D:\tools\Python3.6\lib\threading.py", line 916, in _bootstrap_inner |
4 | self.run() |
5 | File "D:\tools\Python3.6\lib\threading.py", line 864, in run |
6 | self._target(*self._args, **self._kwargs) |
7 | File "D:\tools\Python3.6\lib\subprocess.py", line 1084, in _readerthread |
8 | buffer.append(fh.read()) |
9 | File "D:\tools\Python3.6\lib\codecs.py", line 322, in decode |
10 | (result, consumed) = self._buffer_decode(data, self.errors, final) |
11 | UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 639: invalid continuation byte |
12 | |
13 | Traceback (most recent call last): |
14 | File "D:/zjf_workspace/000、爬虫代码-基础的/scrapy_100_工具/27、将网页html转存成pdf/3、pdfkit模块/2、pdfkit模块--from_file.py", line 6, in <module> |
15 | pdfkit.from_file(['0.html', '1.html'], 'demo5.pdf', configuration=config) |
16 | File "D:\tools\Python3.6\lib\site-packages\pdfkit\api.py", line 49, in from_file |
17 | return r.to_pdf(output_path) |
18 | File "D:\tools\Python3.6\lib\site-packages\pdfkit\pdfkit.py", line 164, in to_pdf |
19 | raise IOError("wkhtmltopdf exited with non-zero code {0}. error:\n{1}".format(exit_code, stderr)) |
20 | OSError: wkhtmltopdf exited with non-zero code 1. error: |
方法5–就是使用python执行系统命令的方法执行前俩个方法,可以做到批量处理。
python执行系统命令的方法主要有下面这三个:
- os.system()
- os.popen()
- subprocess.Popen()
==新增:这三个的区别和方法,可以参考我的另一篇博客==。
python执行系统命令的方法总结
==后续补充新增:三、用自己的方法实现完成将廖雪峰的129页博客保存为一个pdf:==
这个具体我不解释了,就是前面的一个综合,直接上代码吧:
1 | import os |
2 | import subprocess |
3 | |
4 | import requests |
5 | from PyPDF2 import PdfFileWriter, PdfFileReader |
6 | from lxml import etree |
7 | |
8 | |
9 | class Merge_LiaoXueFeng: |
10 | def __init__(self, pdf_name,path): |
11 | self.headers = { |
12 | "Cookie": "Hm_lvt_2efddd14a5f2b304677462d06fb4f964=1571883576; Hm_lpvt_2efddd14a5f2b304677462d06fb4f964=1571884481", |
13 | "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36" |
14 | } |
15 | self.urls = self.get_url_list() |
16 | self.pdf_name = pdf_name |
17 | self.path = path |
18 | |
19 | def get_url_list(self): |
20 | """ |
21 | 获取所有URL目录列表 |
22 | :return: |
23 | """ |
24 | response = requests.get("https://www.liaoxuefeng.com/wiki/1016959663602400", headers=self.headers) |
25 | html = etree.HTML(response.text) |
26 | with open('ret.html', 'w', encoding='utf-8') as file: |
27 | file.write(response.text) |
28 | href_list = html.xpath('//*[@id="x-wiki-index"]//a/@href') |
29 | print("myself_href", href_list) |
30 | urls = [] |
31 | for href in href_list: |
32 | url = "http://www.liaoxuefeng.com" + href |
33 | urls.append(url) |
34 | return urls |
35 | |
36 | def merge_pdf(self, infnList, outfn): |
37 | """ |
38 | 合并pdf |
39 | :return: |
40 | """ |
41 | pdf_output = PdfFileWriter() |
42 | # 把所有pdf写入一个pdf(pdf合并) |
43 | for infn in infnList: |
44 | pdf_input = PdfFileReader(open(infn, 'rb')) |
45 | # 获取 pdf 共用多少页,把每一个pdf的所有页数写进一个pdf |
46 | page_count = pdf_input.getNumPages() |
47 | print(page_count) |
48 | for i in range(page_count): |
49 | pdf_output.addPage(pdf_input.getPage(i)) |
50 | pdf_output.write(open(outfn, 'wb')) |
51 | |
52 | def get_pdf_list(self): |
53 | """ |
54 | 获取当前位置的pdf目录下的所有pdf的绝对路径,返回为pdf路径列表 |
55 | :return: |
56 | """ |
57 | # 获取当前pdf目录下的所以pdf文件 |
58 | # path = os.getcwd(r"D:\zjf_workspace\000、爬虫代码-基础的\scrapy_100_工具\27、将网页html转存成pdf\1、批量处理") |
59 | html_path = os.path.join(self.path, 'pdf') |
60 | file_list = os.listdir(html_path) |
61 | pdf_list = [] |
62 | for file_one in file_list: |
63 | # 判断是否都是pdf文件 |
64 | if file_one.endswith('.pdf'): |
65 | pdf_file = os.path.join(html_path, file_one) |
66 | pdf_list.append(pdf_file) |
67 | return pdf_list |
68 | |
69 | def run(self): |
70 | num = 0 |
71 | subprocess_list = [] |
72 | # 1、保存文章为pdf |
73 | for article_url in self.urls: |
74 | num += 1 |
75 | # 不等待结束接着运行下一个,(不建议很多运行,可以五个左右设置一个等待完成,防止多个运行电脑卡死) |
76 | subprocess_one = subprocess.Popen(r'wkhtmltopdf {} ./pdf/{}.pdf'.format(article_url, num)) |
77 | subprocess_list.append(subprocess_one) |
78 | if len(subprocess_list) >= 10: |
79 | for i in subprocess_list: |
80 | i.wait() |
81 | subprocess_list = [] |
82 | else: |
83 | pass |
84 | # os_one = os.popen(r'wkhtmltopdf {} ./pdf2/{}.pdf'.format(article_url, num)) |
85 | # os_one.close() |
86 | # print(dir(os_one)) |
87 | # time.sleep(20) |
88 | # 一个运行结束另一个运行(可以加个协程跑快一点) |
89 | # os.system(r'wkhtmltopdf {} ./pdf3/{}.pdf'.format(article_url, num)) |
90 | |
91 | # 最后可能不大于10,所有把后面小于10的执行完毕 |
92 | for i in subprocess_list: |
93 | i.wait() |
94 | |
95 | # 2、获取当前pdf目录下的所以pdf文件 |
96 | pdf_list = self.get_pdf_list() |
97 | print("pdf_list",pdf_list) |
98 | |
99 | # 3、合并pdf |
100 | print('pdf下载完毕,准备合并pdf:') |
101 | self.merge_pdf(pdf_list, self.pdf_name) |
102 | |
103 | |
104 | if __name__ == '__main__': |
105 | path = os.getcwd() |
106 | print(path) |
107 | liaoxuefeng = Merge_LiaoXueFeng(u"廖雪峰Python_all.pdf", path) |
108 | liaoxuefeng.run() |
最终效果:
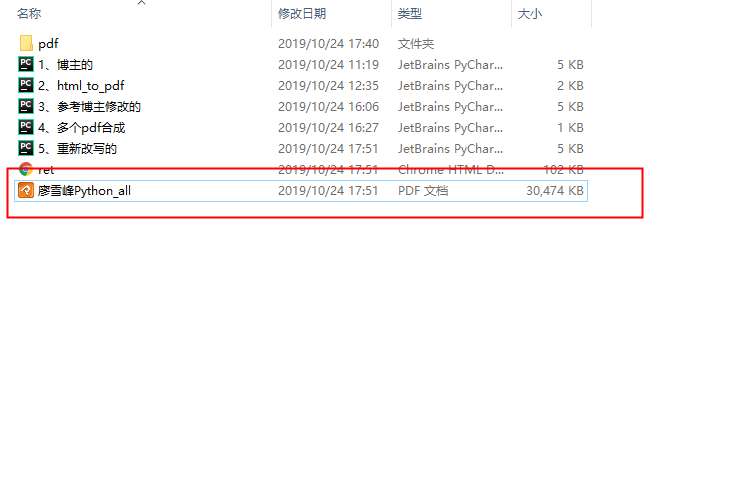
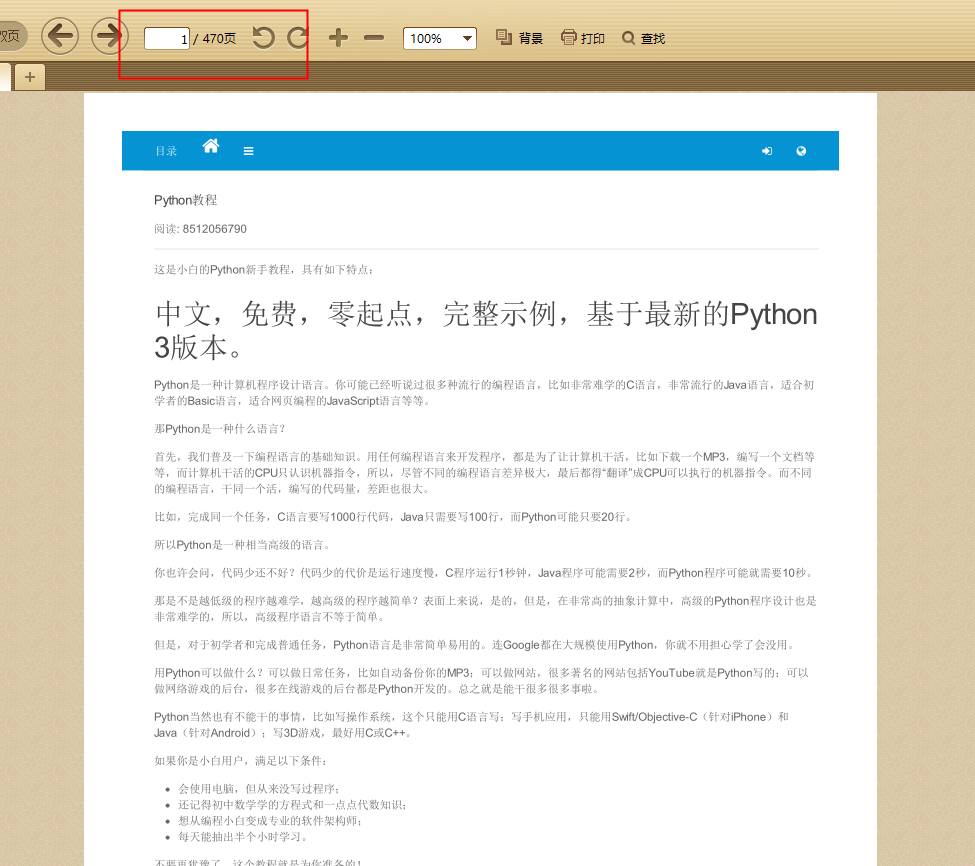
学习参考文章:
https://blog.csdn.net/hubaoquanu/article/details/66973149
https://blog.csdn.net/y101101025/article/details/62461115
https://blog.csdn.net/u012561176/article/details/83655247
https://blog.csdn.net/xc_zhou/article/details/80952168

