@[toc]
一、说明:
这个是我发现一个python好用的一个模块,名字就是pinyin:
主要功能就是基于普通话将汉字翻译成拼音。
安装命令:
1 | pip install pinyin |
二、简单使用:
解释我放在代码里面了,看看就懂了,不过多解释了。
1、汉字转拼音:
1 | import pinyin |
2 | |
3 | # 1、可以获取拼音和音调 |
4 | # print(pinyin.get('你 好')) |
5 | print(pinyin.get('我爱你')) |
6 | # 2、只获取拼音词 |
7 | # print(pinyin.get('你好', format="strip", delimiter=" ")) |
8 | print(pinyin.get('小时候,我害怕黑夜', format="strip", delimiter=" ")) |
9 | |
10 | # 3、获取拼音,后面跟的是音调(1-4) |
11 | # print(pinyin.get('你好', format="numerical")) |
12 | print(pinyin.get('我爱你', format="numerical")) |
13 | |
14 | # 4、获取汉字的拼音首字母 |
15 | print(pinyin.get_initial('你好')) |
运行结果:
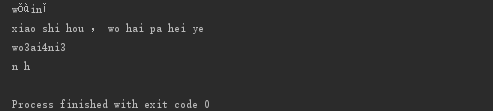
在这里插入图片描述
2、汉字转英文(不能转换一个句子,如果是句子会先切分开再进行一个一个翻译,返回列表)
1 | import pinyin.cedict |
2 | |
3 | |
4 | # 1、这个只能翻译出单个词,不能翻译一个句子或者短语,只能是字或者词 |
5 | result = pinyin.cedict.translate_word('你') |
6 | print(result) |
7 | result = pinyin.cedict.translate_word('我爱你') |
8 | print(result) |
9 | result = pinyin.cedict.translate_word('中国') |
10 | print(result) |
11 | |
12 | # 2、这个是相当于返回一个上面的列表,自动把词分开(不建议翻译一个句子) |
13 | print("*"*20) |
14 | result = list(pinyin.cedict.all_phrase_translations('你好')) |
15 | print(result) |
16 | result = list(pinyin.cedict.all_phrase_translations('我爱你')) |
17 | print(result) |
18 | result = list(pinyin.cedict.all_phrase_translations('我爱你中国')) |
19 | print(result) |
运行结果:
1 | ['you (informal, as opposed to courteous 您[nin2])'] |
2 | None |
3 | ['China'] |
4 | ******************** |
5 | [['你', ['you (informal, as opposed to courteous 您[nin2])']], ['你好', ['Hello!', 'Hi!', 'How are you?']], ['好', ['to be fond of', 'to have a tendency to', 'to be prone to']]] |
6 | [['我', ['I', 'me', 'my']], ['爱', ['to love', 'to be fond of', 'to like', 'affection', 'to be inclined (to do sth)', 'to tend to (happen)']], ['你', ['you (informal, as opposed to courteous 您[nin2])']]] |
7 | [['我', ['I', 'me', 'my']], ['爱', ['to love', 'to be fond of', 'to like', 'affection', 'to be inclined (to do sth)', 'to tend to (happen)']], ['你', ['you (informal, as opposed to courteous 您[nin2])']], ['中', ['to hit (the mark)', 'to be hit by', 'to suffer', 'to win (a prize, a lottery)']], ['中国', ['China']], ['国', ['country', 'nation', 'state', 'national', 'CL:個|个[ge4]']]] |

