一、说明:
本文是基于谷歌翻译的一次爬虫学习,开始是基于模块的学习使用,然后自己尝试了js逆向的使用。
二、 googletrans模块的学习使用:
1、安装:
1 | pip install googletrans |
2、简单使用:
1、基本翻译的用法(也是常用的用法):
这个区别什么的我放到代码中解释了,一看就懂了,我就不过多解释了。
1 | from googletrans import Translator |
2 | translator = Translator() |
3 | # 1、不定位输入语言,不指定输出语言(会自动默认输出为英文,然后翻译成英文) |
4 | result1 = translator.translate('你好,我是中国人') |
5 | print("result1",result1) |
6 | print("result1",result1.text) |
7 | # 2、不定位输入语言,指定输出语言 |
8 | result2 = translator.translate('你好,我是中国人', dest='en') |
9 | print("result2",result2) |
10 | print("result2",result2.text) |
11 | |
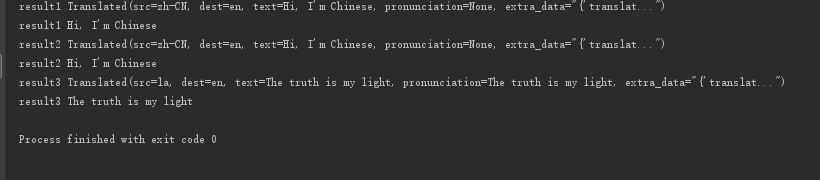
12 | # 3、指定输入语言,不指定输出(默认输出为英语) |
13 | # result3 = translator.translate('你好,我是中国人', src='la') |
14 | result3 = translator.translate('veritas lux mea', src='la') |
15 | print("result3", result3) |
16 | print("result3", result3.text) |
在这里插入图片描述
2、检测文本语言:
这个我感觉不错,比如,刚开始我使用时我就不知道如果使用英文翻译成中文,然后就使用检测出来的。
1 | from googletrans import Translator |
2 | translator = Translator() |
3 | print(translator.detect('일요일')) |
4 | print(translator.detect('你好')) |
5 | |
6 | # Detected(lang=ko, confidence=1.0) |
7 | # Detected(lang=zh-CN, confidence=1.0) |
这个结果正好把中文给我返回处来。也知道英文如何翻译成中文了。
然后我看下源码,也知道为什么不写输出语言,给我返回英文了。其实人家都写好了,不知道就按英文来翻译。
在这里插入图片描述
3、英文翻译成中文(其他语言类似):
(其他语言类似,先随意输入目标语言,检测出谷歌翻译参数dest的固定字符串,然后更改目标语言dest即可)
1 | from googletrans import Translator |
2 | translator = Translator() |
3 | text = 'You can use another google translate domain for translation. If multiple URLs are provided it then randomly chooses a domain.' |
4 | print(translator.translate(text, dest='zh-CN').text) |
翻译结果:

在这里插入图片描述
4、多个句子翻译:
1 | from googletrans import Translator |
2 | |
3 | translator = Translator() |
4 | |
5 | # 这个是官方的方法,可以一次性翻译好几个,但是实际中,如果句子比较长,我还是建议下面循环翻译 |
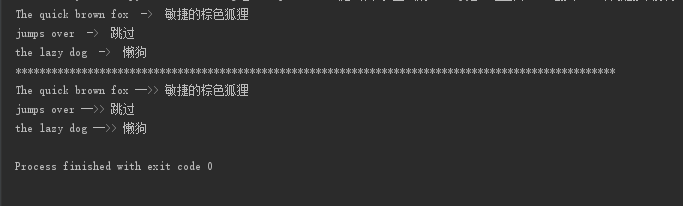
6 | translations = translator.translate(['The quick brown fox', 'jumps over', 'the lazy dog'], dest='zh-CN') |
7 | for translation in translations: |
8 | print(translation.origin, ' -> ', translation.text) |
9 | |
10 | print("*" * 100) |
11 | # 我建议寻找一个一个翻译比较好,这样如果我要翻译的有很多条,每个也比较长,这种效率快一点。 |
12 | text_list = ['The quick brown fox', 'jumps over', 'the lazy dog'] |
13 | for text in text_list: |
14 | translation = translator.translate(text,dest='zh-CN') |
15 | print(translation.origin,"-->>",translation.text) |
翻译结果:
在这里插入图片描述
三、JS解密翻译:
这个我是先参考了一个博客,然后又自己动手找到一个加密位置,但是我也有个好奇,我找到的和人家的不一样,最后的tk不一样,结果竟然获取的结果都可以使用,不知道什么原因,如果有大佬看到,欢迎给我讲讲哈。
1、参考博主解密的:
js直接复制参考博主的,简单翻译一下。
1 | import json |
2 | from urllib import parse |
3 | |
4 | import execjs |
5 | import requests |
6 | |
7 | |
8 | def get_tk(text): |
9 | ctx = execjs.compile(""" |
10 | function TL(a) { |
11 | var k = ""; |
12 | var b = 406644; |
13 | var b1 = 3293161072; |
14 | var jd = "."; |
15 | var $b = "+-a^+6"; |
16 | var Zb = "+-3^+b+-f"; |
17 | for (var e = [], f = 0, g = 0; g < a.length; g++) { |
18 | var m = a.charCodeAt(g); |
19 | 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 + ((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), |
20 | e[f++] = m >> 18 | 240, |
21 | e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, |
22 | e[f++] = m >> 6 & 63 | 128), |
23 | e[f++] = m & 63 | 128) |
24 | } |
25 | a = b; |
26 | for (f = 0; f < e.length; f++) a += e[f], |
27 | a = RL(a, $b); |
28 | a = RL(a, Zb); |
29 | a ^= b1 || 0; |
30 | 0 > a && (a = (a & 2147483647) + 2147483648); |
31 | a %= 1E6; |
32 | return a.toString() + jd + (a ^ b) |
33 | }; |
34 | function RL(a, b) { |
35 | var t = "a"; |
36 | var Yb = "+"; |
37 | for (var c = 0; c < b.length - 2; c += 3) { |
38 | var d = b.charAt(c + 2), |
39 | d = d >= t ? d.charCodeAt(0) - 87 : Number(d), |
40 | d = b.charAt(c + 1) == Yb ? a >>> d: a << d; |
41 | a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d |
42 | } |
43 | return a |
44 | } |
45 | """) |
46 | |
47 | # text = '北京欢乐谷是国家AAAA级旅游景区、新北京十六景、北京文化创意产业基地' |
48 | tk = ctx.call("TL", text) |
49 | return tk |
50 | |
51 | |
52 | def get_translate(text): |
53 | tk = get_tk(text) |
54 | url = 'https://translate.google.com/translate_a/single?client=webapp&sl=auto&tl=en&hl=zh-TW&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&dt=gt&ssel=3&tsel=3&kc=0&' |
55 | headers = { |
56 | "cookie": '1P_JAR=2019-11-13-9;_gid=GA1.3.73678266.1573636802;_ga=GA1.3.640150160.1573636802;NID=191=ItRAUI4OCeQtUgD3QoKbIxx0ny7FA29sz5mf86s9OWsierCx8kk1aIBAGSpKZ_Rn3QxzPseewMmG1b97DL6fFA_JCjsZxMrMAhLjv3EHyRvIkd0Y5ah0tkfAMvxyhSNX6VNZncmReWyjxdk4cbJQR57c4MDlNOs0lTraa-Ten1s', |
57 | "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36", |
58 | } |
59 | params = { |
60 | "tk": tk, |
61 | "q": text |
62 | } |
63 | url_encode_params = parse.urlencode(params) |
64 | url_params = url + url_encode_params |
65 | # print('url_params', url_params) |
66 | resp2 = requests.get(url_params, headers=headers) |
67 | # print('resp2', resp2.status_code, resp2.text) |
68 | data = json.loads(resp2.text) |
69 | translate_en_text = data[0][0][0] |
70 | print("tk1",tk) |
71 | print("translate_en_text", translate_en_text) |
72 | return translate_en_text |
73 | |
74 | |
75 | if __name__ == '__main__': |
76 | text = '前面介绍了有道翻译接口 破解,接下来试一试谷歌翻译(Github项目地址)同样,查看首页元素' |
77 | translate_en_text = get_translate(text) |
翻译结果:

在这里插入图片描述
2、自己扣得js解密:
1 | import json |
2 | from urllib import parse |
3 | |
4 | import execjs |
5 | import requests |
6 | |
7 | |
8 | def get_tk(text): |
9 | ctx = execjs.compile(""" |
10 | |
11 | var vo = function(a) { |
12 | return function() { |
13 | return a |
14 | } |
15 | } |
16 | var xo = "437117.4102146620" |
17 | var wo = function(a, b) { |
18 | for (var c = 0; c < b.length - 2; c += 3) { |
19 | var d = b.charAt(c + 2); |
20 | d = "a" <= d ? d.charCodeAt(0) - 87 : Number(d); |
21 | d = "+" == b.charAt(c + 1) ? a >>> d : a << d; |
22 | a = "+" == b.charAt(c) ? a + d & 4294967295 : a ^ d |
23 | } |
24 | return a |
25 | } |
26 | |
27 | |
28 | function get_tk(a) { |
29 | if (null !== xo) |
30 | var b = xo; |
31 | else { |
32 | b = vo(String.fromCharCode(84)); |
33 | var c = vo(String.fromCharCode(75)); |
34 | b = [b(), b()]; |
35 | b[1] = c(); |
36 | b = (xo = window[b.join(c())] || "") || "" |
37 | } |
38 | var d = vo(String.fromCharCode(116)); |
39 | c = vo(String.fromCharCode(107)); |
40 | d = [d(), d()]; |
41 | d[1] = c(); |
42 | c = "&" + d.join("") + "="; |
43 | d = b.split("."); |
44 | b = Number(d[0]) || 0; |
45 | for (var e = [], f = 0, g = 0; g < a.length; g++) { |
46 | var k = a.charCodeAt(g); |
47 | 128 > k ? e[f++] = k : (2048 > k ? e[f++] = k >> 6 | 192 : (55296 == (k & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (k = 65536 + ((k & 1023) << 10) + (a.charCodeAt(++g) & 1023), |
48 | e[f++] = k >> 18 | 240, |
49 | e[f++] = k >> 12 & 63 | 128) : e[f++] = k >> 12 | 224, |
50 | e[f++] = k >> 6 & 63 | 128), |
51 | e[f++] = k & 63 | 128) |
52 | } |
53 | a = b; |
54 | for (f = 0; f < e.length; f++) |
55 | a += e[f], |
56 | a = wo(a, "+-a^+6"); |
57 | a = wo(a, "+-3^+b+-f"); |
58 | a ^= Number(d[1]) || 0; |
59 | 0 > a && (a = (a & 2147483647) + 2147483648); |
60 | a %= 1E6; |
61 | return (a.toString() + "." + (a ^ b)) |
62 | } |
63 | """) |
64 | # text = '北京欢乐谷是国家AAAA级旅游景区、新北京十六景、北京文化创意产业基地' |
65 | tk = ctx.call("get_tk", text) |
66 | return tk |
67 | |
68 | |
69 | def get_translate(text): |
70 | tk = get_tk(text) |
71 | url = 'https://translate.google.com/translate_a/single?client=webapp&sl=auto&tl=en&hl=zh-TW&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&dt=gt&ssel=3&tsel=3&kc=0&' |
72 | headers = { |
73 | "cookie": "HSID=A9q8G-FPNx6QwfqlY; SSID=AyWKCt0aKhDNPLqW6; APISID=52CYB7USRLRyBkFl/AhucACQCyF5bkzMIM; SAPISID=7sAQYqTKCyubismp/A6GCzfKGnLisIiTpM; CONSENT=YES+US.zh-CN+; SID=pwdbenXUSnGz056YdylCL-ZDrCLJaIvqrUBKGvbe-HJ3s48yPBi9Mk7RYGFZ_o-kZZQ8Rg.; SEARCH_SAMESITE=CgQIoI4B; NID=191=WdhY3hdbpEdpGhDLxFUrnkFmgSrStymg9kBM-9FHyoaLOVIqx9Z7KtAtA_dtCNJj4d8xyJ_9WlkJ0sCFlzavlyYl-tUoIy4hdz2E5j6p3Nbc1uoyEOb_9AmNmdHMngO-yPxj5Mxb8ervFTzp4drfWUogmwuY3HAGldxDJYBlvzoHJb8Rzr4OtPhbP0TGO_mmh9UChE5WPSHLfX-3KUwUb5pm1tixJYNMec-WULuOaLUIQD0EPnnbRY9CXhEfLA; 1P_JAR=2019-11-13-5; _ga=GA1.3.658002031.1573624431; _gid=GA1.3.1337733321.1573624431; SIDCC=AN0-TYvUIyqWcavZaG_swbs9zSM1oMD8nXPSQVzxV5ndURyHBY2CueYI1jCM3Wm7XIaoA-57ag", |
74 | "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36", |
75 | } |
76 | params = { |
77 | "tk": tk, |
78 | "q": text |
79 | } |
80 | url_encode_params = parse.urlencode(params) |
81 | url_params = url + url_encode_params |
82 | # print('url_params', url_params) |
83 | resp2 = requests.get(url_params, headers=headers) |
84 | # print('resp2', resp2.text) |
85 | data = json.loads(resp2.text) |
86 | translate_en_text = data[0][0][0] |
87 | print("translate_en_text", translate_en_text) |
88 | return translate_en_text |
89 | |
90 | |
91 | if __name__ == '__main__': |
92 | text = '前面介绍了有道翻译接口 破解,接下来试一试谷歌翻译(Github项目地址)同样,查看首页元素' |
93 | translate_en_text = get_translate(text) |
翻译结果:
 在这里插入图片描述
在这里插入图片描述
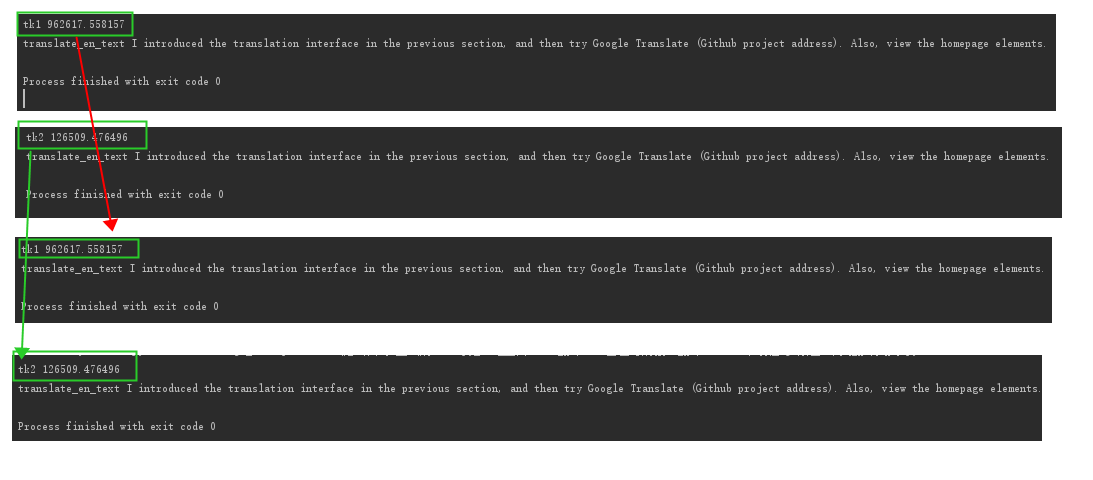
3、对比,有个疑惑:
在这里插入图片描述
通过俩个相同的句子,得到的加密的tk不一样,却能获取到结果,不知道为什么,而且我第一次以为每次加密的结果是随机数生成呐,我的和参考博主的,各自的加密tk结果多次运行是一样的,如果有懂的大佬,欢迎给我解解疑惑,指点一下哈。

