本次分析爬虫中的寻找响应乱码,找到正确编码格式的俩种方法:
方法1、浏览器查找charset
编码加密,一般响应之后进行解码即可,但是除了单个字体js加密的除外,那种需要其他方法。
一般编码格式有utf-8、gbk、gb2312,如果preview和response的内容一直,则编码就是utf-8.
如下加密情况,可以看出不是utf-8的编码格式,需要进行对应的解码:
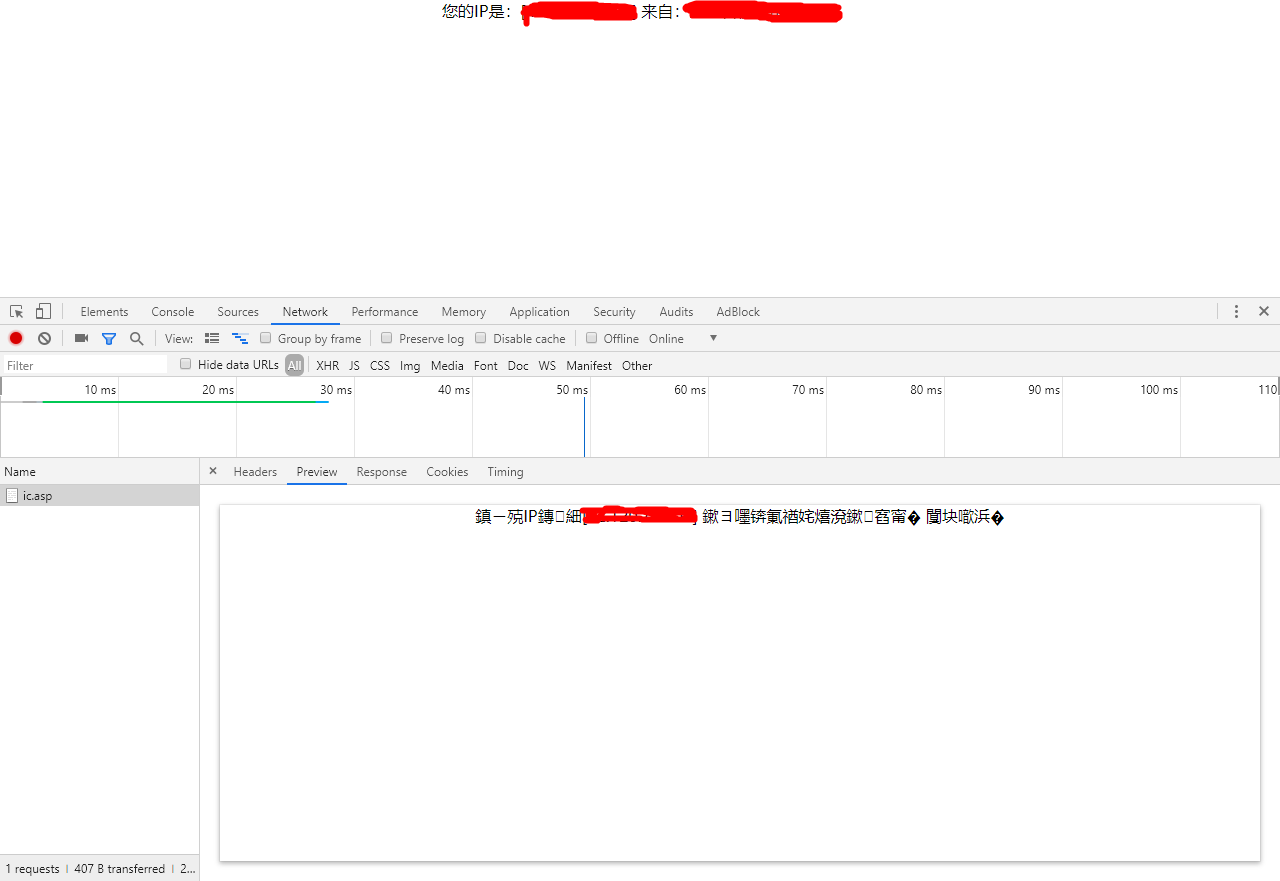
在这里插入图片描述

在这里插入图片描述
然而响应的内容却是正常的,从文中找到charset,所以我觉得就是gb2312的编码格式,尝试结果就是。
所以这就给我提供一个思路,如果在遇到响应乱码时,可以再浏览器中搜索charset,进行尝试。
方法2:使用chardet模块
大多数情况下是可以适用的,也会存在一定的识别错误情况。
安装:
pip install chardet
具体代码中的简单使用:
import chardet
url = "http://2019.ip138.com/ic.asp"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
resp = requests.get(url=url, headers=headers, timeout=2)
cs = chardet.detect(resp.content)
print("cs的类型:{0}".format(type(cs)))
print("监测到的cs数据:{0}".format(cs))输出结果:
cs的类型:<class ‘dict’>
监测到的cs数据:{‘encoding’: ‘GB2312’, ‘confidence’: 0.99, ‘language’: ‘Chinese’}
encoding对应的值就是编码格式。confidence对应的值时识别正确率。

