说明:
今天就是想做一个使用scrapy爬取网页时携带cookie或者其他请求头时,携带的有效性方法,进行验证:
我的验证思路:
测试网站是CSDN的写作榜单,使用登录和未登录的cookies对比,对返回的响应是否含有自己的用户名,来进行验证是否携带成功。
一、使用requests模块初步验证cookies的有效性:
1、先分析页面结构:
做爬虫一定要先分析,学会分析才能接着往下做的更快,分析的时间远远大于自己写代码的时间(反正我的日常工作,是这样,分析最占时间,有时候需要结合代码测试着,边测试请求边分析,这都是很正常的)
①、登录状态
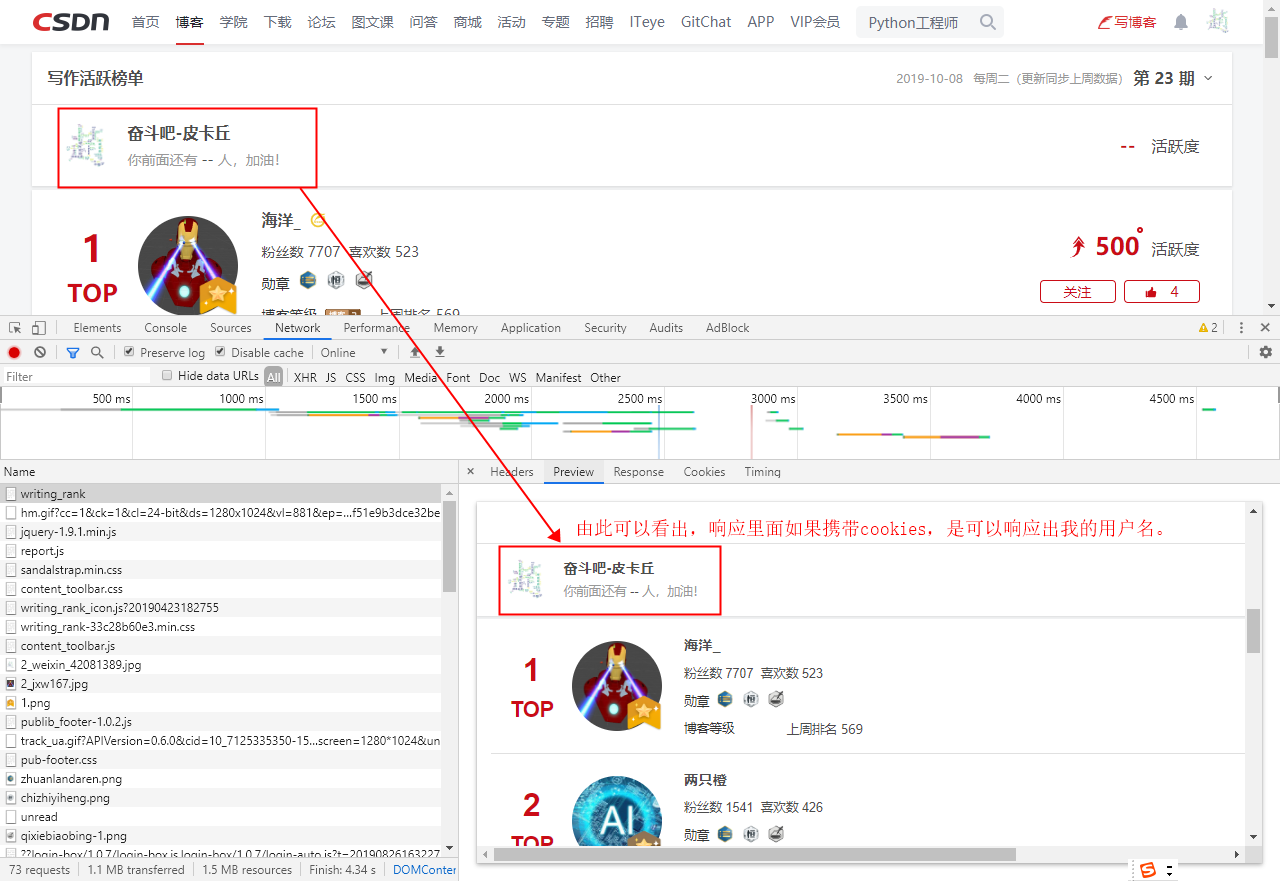
再次精确的验证确实是含有登录信息的。
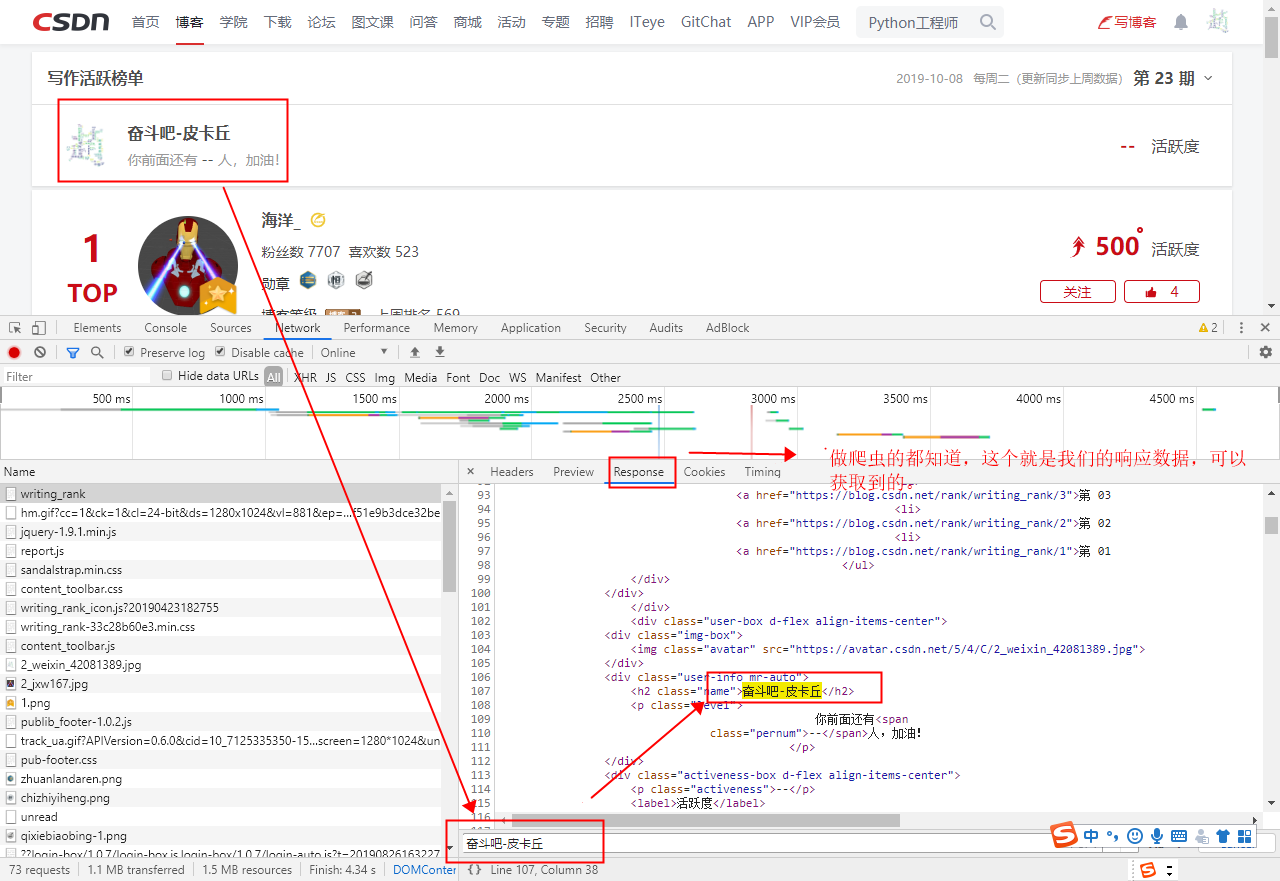
②、未登录状态
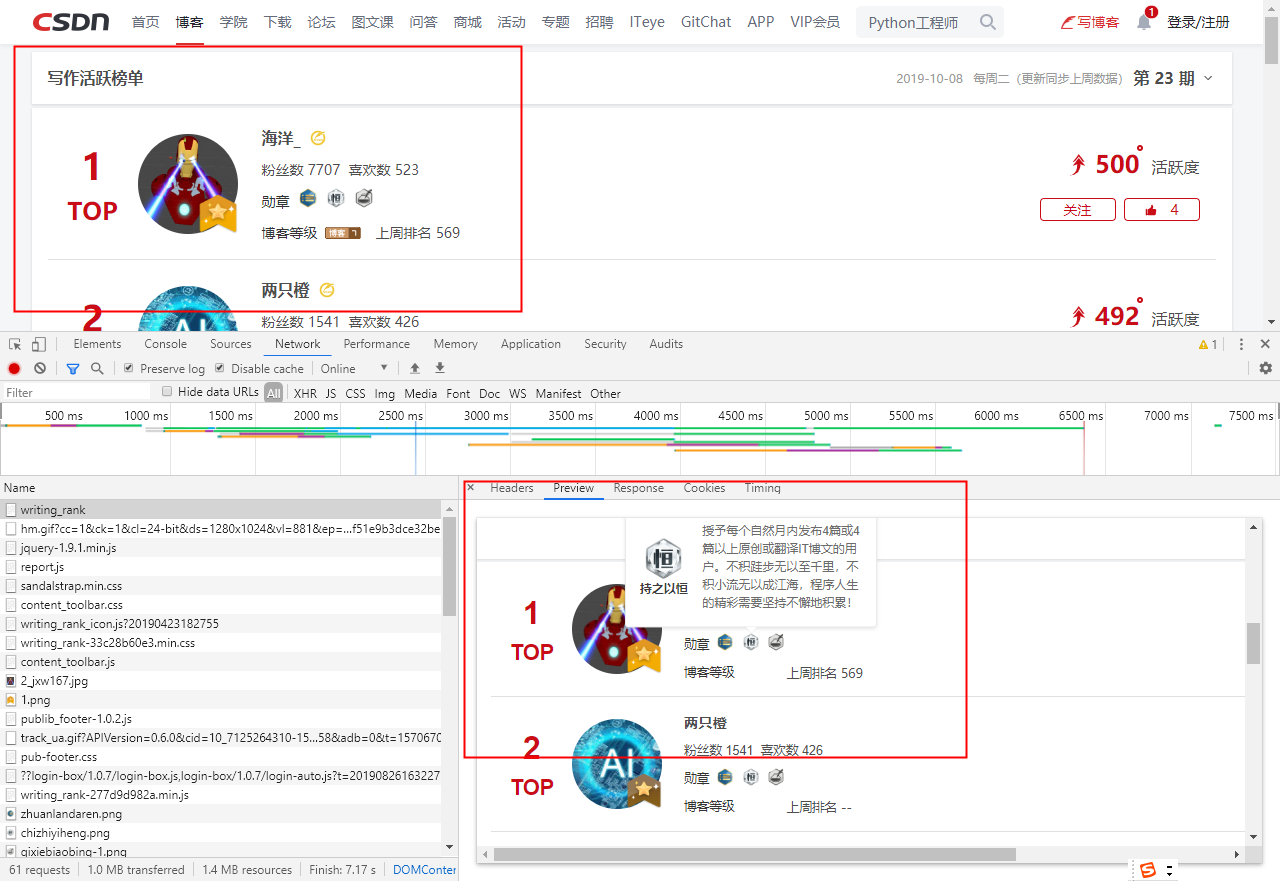
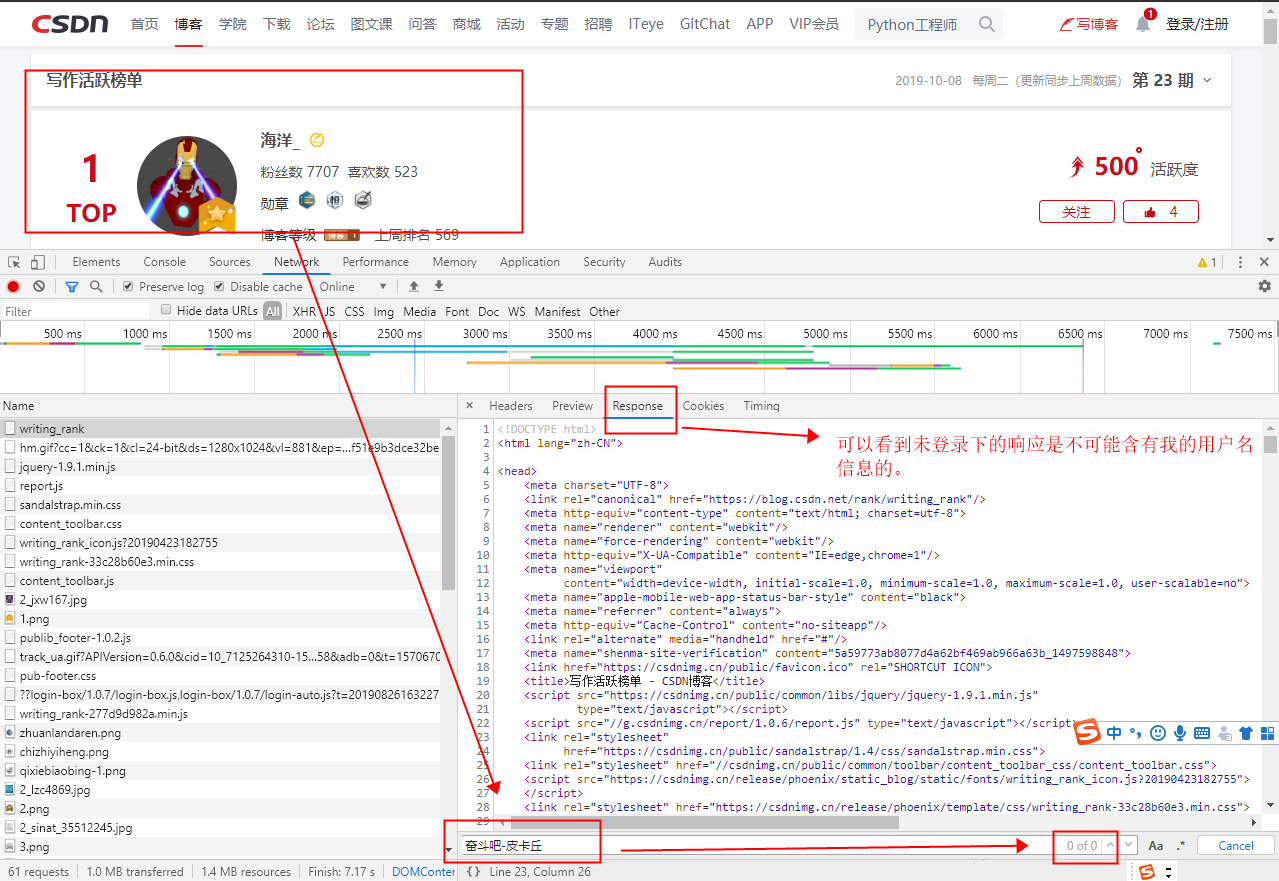
③、对比结论:
通过登录和未登录的状态对比,可以体现出cookies的有效性。
2、接下来我们使用requests模块测试cookies的有效性:
①、测试代码:
1 | import requests |
2 | |
3 | url = "https://blog.csdn.net/rank/writing_rank" |
4 | |
5 | headers = { |
6 | "Cookie": "acw_tc=2760826b15706703138356750ef0504a5c53f64ccc4b649607aa0b0ffab95d; uuid_tt_dd=10_7125264310-1570670313837-927472; dc_session_id=10_1570670313837.951940; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1570670317; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7125264310-1570670313837-927472; firstDie=1; dc_tos=pz4wzc; c-login-auto=2; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1570670329", |
7 | # "Host": "blog.csdn.net", |
8 | # "Pragma": "no-cache", |
9 | # "Sec-Fetch-Mode": "navigate", |
10 | # "Sec-Fetch-Site": "none", |
11 | # "Sec-Fetch-User": "?1", |
12 | # "Upgrade-Insecure-Requests": "1", |
13 | "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" |
14 | } |
15 | |
16 | resp = requests.get(url,headers=headers) |
17 | |
18 | # print(resp.text) |
19 | print("是否有我的登陆信息", "奋斗吧-皮卡丘" in resp.text) |
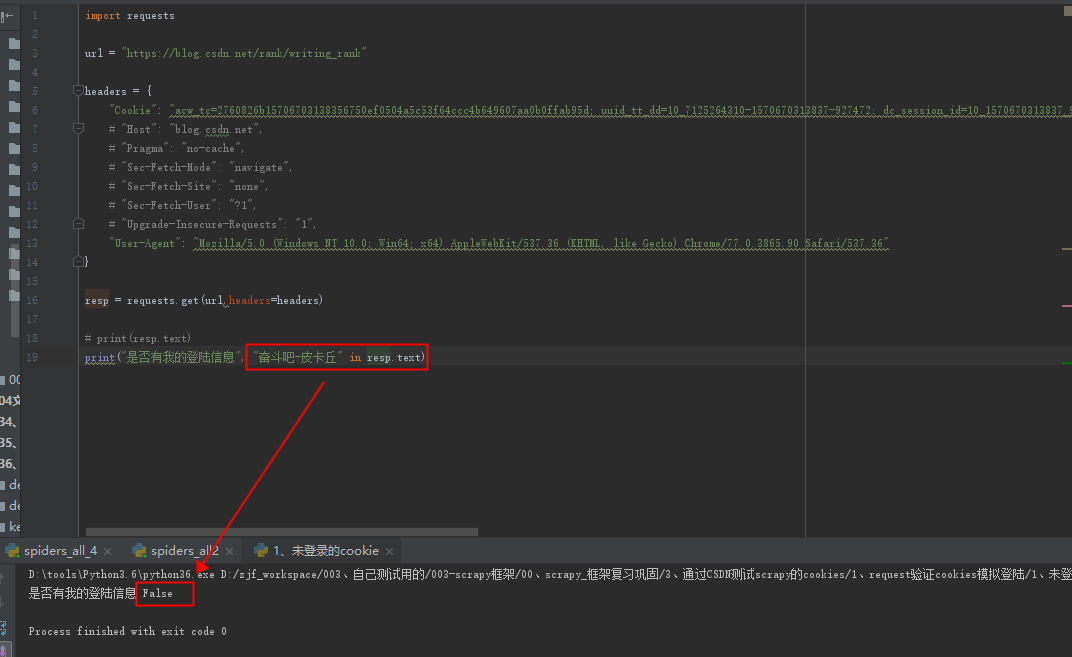
②、未登录状态
发现找不到我的用户名,结果是False
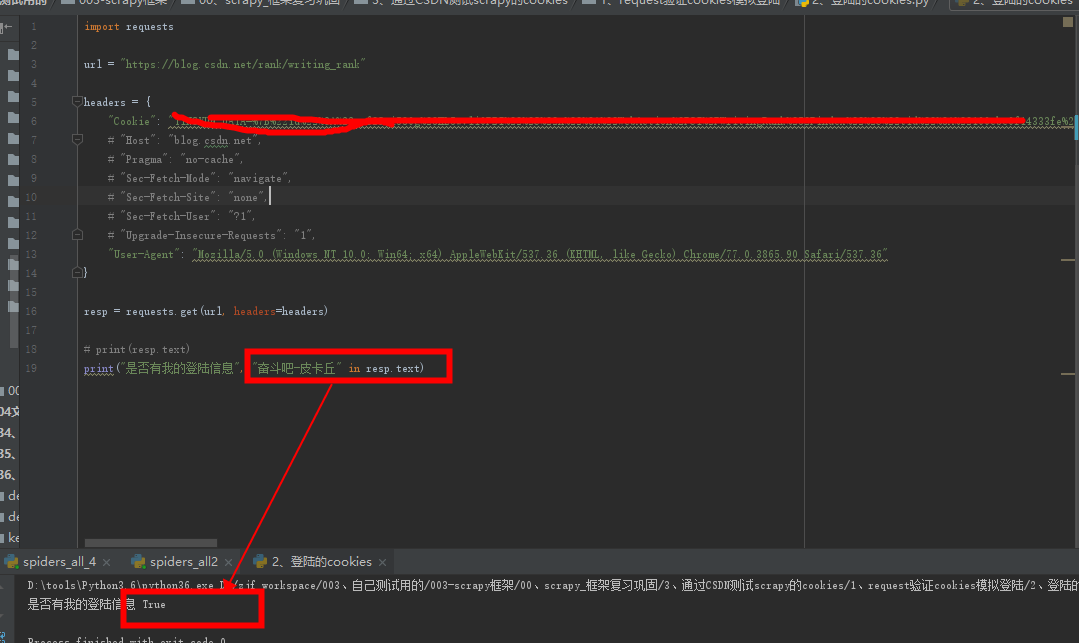
③、登录状态
这个代码只是cookie改了,其他不变,你可以改成你自己的,这个返回是True,当然,用户名代码中也要改为你自己的。
④、结论
通过对此测试,从而证明了。携带cookies是否有效,可以影响是否可以从响应中找到自己的用户名。
二、使用scrapy测试携带cookie的方法
1、命令生成项目和初始化爬虫:
1 | scrapy startproject CSDN_writing |
2 | cd .\CSDN_writing\ |
3 | scrapy genspider csdn1 blog.csdn.net |
默认生成模板。
2、修改setting
记得把ROBOTSTXT_OBEY 改为False,其他几个可以直接复制过去。
1 | # ROBOTSTXT_OBEY = True |
2 | USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' |
3 | ROBOTSTXT_OBEY = False |
4 | |
5 | _LEVEL = 'DEBUG' |
6 | LOG_LEVEL = "WARNING" |
3、初步更改爬虫程序
这里我只是更改了初始的url,其他就是在进入解析函数,打印出url,进行测试。
其他的items.py 和管道pipelines.py我们可以不用修改(因为我们不存数据,不需要进入管道,如果需要存数据再进行更改即可,如果更改pipelines.py,记得把setting的注销代码打开,默认模板中是关闭的),
1 | # -*- coding: utf-8 -*- |
2 | import scrapy |
3 | |
4 | |
5 | class Csdn1Spider(scrapy.Spider): |
6 | name = 'csdn1' |
7 | allowed_domains = ['blog.csdn.net'] |
8 | start_urls = ['https://blog.csdn.net/rank/writing_rank'] |
9 | |
10 | def parse(self, response): |
11 | print("进入解析函数",response.url) |
12 | # pass |
4、运行测试:

发现,现在可以进入了解析函数,那么我们继续测试没有添加cookies的情况下,看看是否含有用户名,和一会加入cookies做对比。
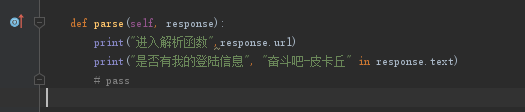

测试结果为False,然后我们测试给start_urls,如何加cookies。
5、start_urls是交给谁处理的呐
根据scrapy生成的模板结构,我们可以发现,我们可以根据通过spiders这个应该能找到关于start_urls处理的函数。
然后在spiders目录下,一个一个搜索,看看具体在哪个里面处理的。
1、init.py文件找到了(应该就是这里,以防万一,我们继续查找)
2、crawl.py文件(我们没有找到)
3、feed.py文件(我们没有找到)
4、init.py文件我们没有找到
5、sitemap.py文件我们没有找到
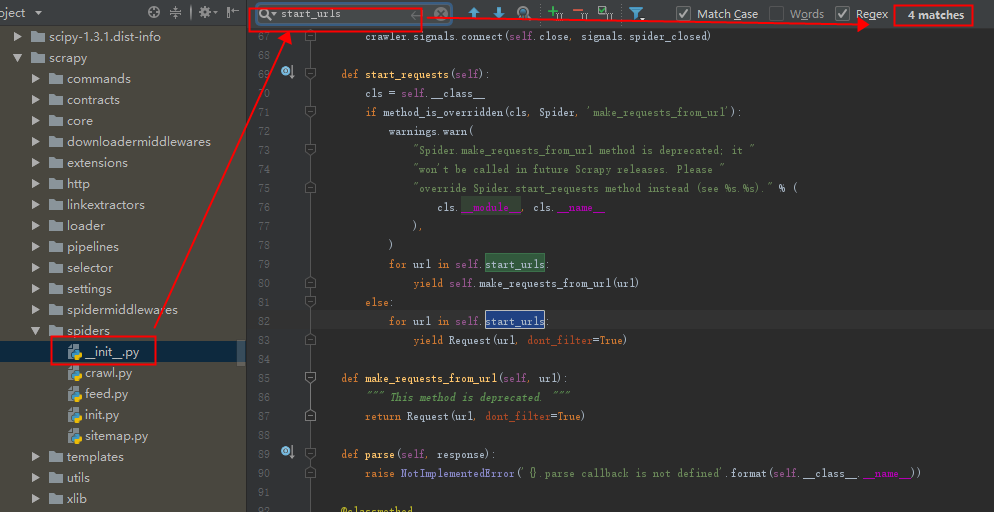
通过以上步骤,我们找到了处理start_urls的位置,这样下来,我们是否理解更深刻了呐。
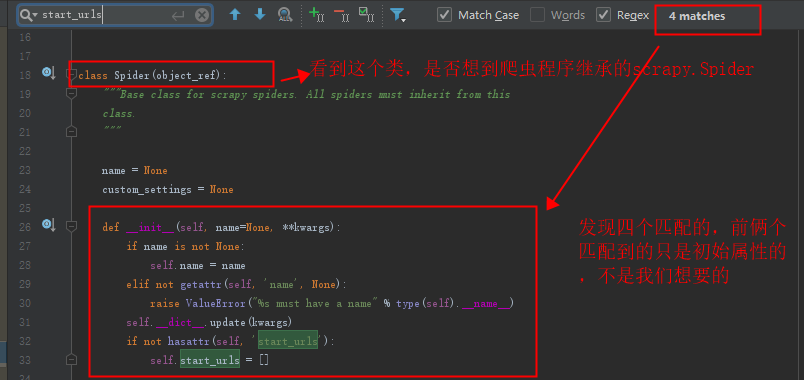

不知道看到这里你有没有想到要进入进行的类,进去看看,更直接的找到处理start_urls的方法位置呐?
进来之后发现就是我们刚刚大费周折要找的位置。但是这样你也就更能理解继承的知识点了。
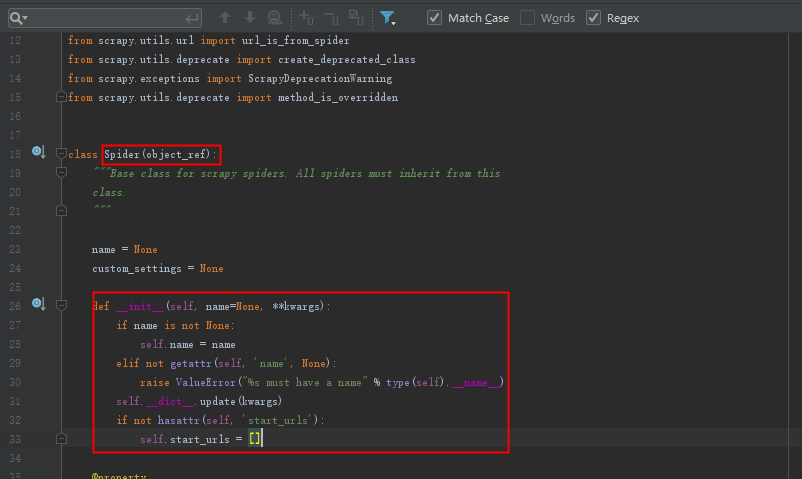
接着寻找:
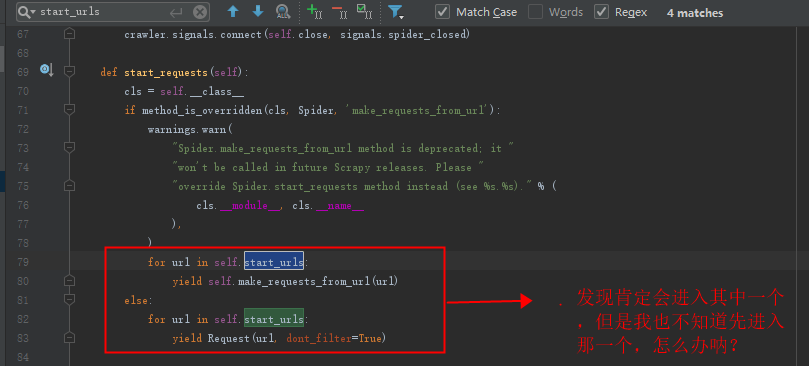
修改源码,测试到底进入哪一个:
然后弹出是否确定编辑,点击ok即可(不要乱改,如果必须更改原内容,尽量先复制一份,改不好还能改回来)。
我改好了,就加个打印,测试到底进入哪一个。
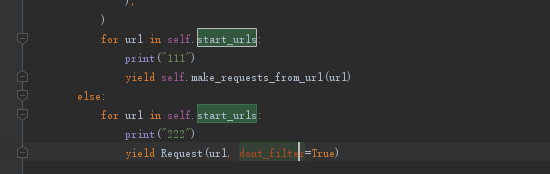
执行爬虫程序,等待打印结果。

这时候我们就知道如何改了,我们可以自定义一个start_requests,这样就不会继承父类的方法了(这样是不是回顾了继承的知识点)
如果还不懂,咱们就看看源文档,
我在这里:
https://doc.scrapy.org/en/latest/topics/spiders.html
找到一段代码就是我们想要的,可以再发送start_urls之前,添加cookis。
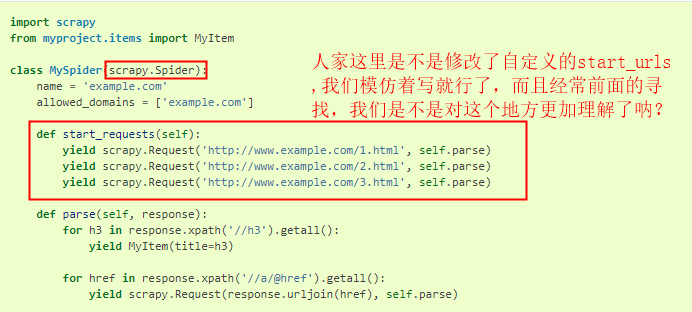
6、经过多次尝试找到添加cookies的方法:
我踩的坑1:
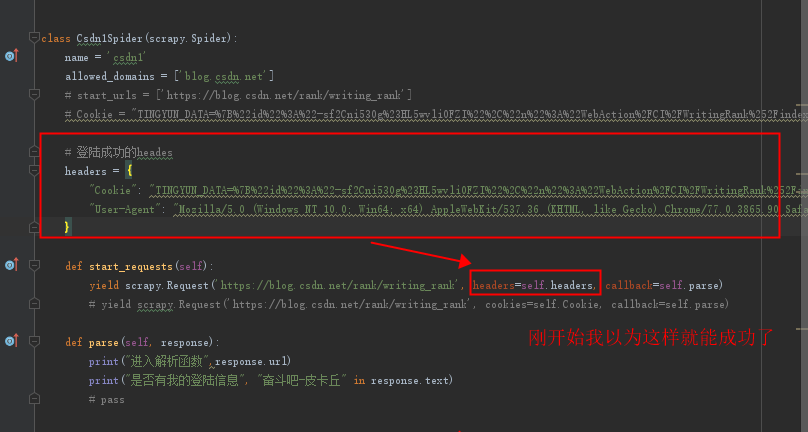
后来运行不出来,

然后我就看看里面的cookies参数:
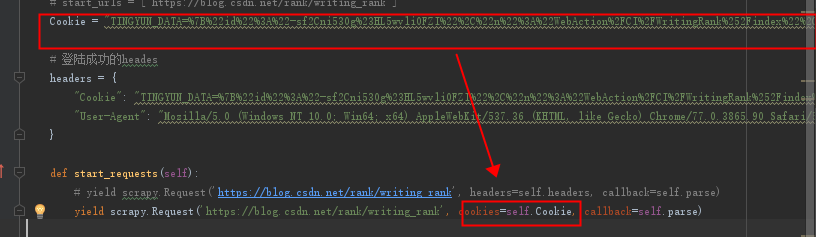
然后报错,我觉得是我的cookies格式不对。

进入源码,查看cookies的接受格式。发现是字典格式:
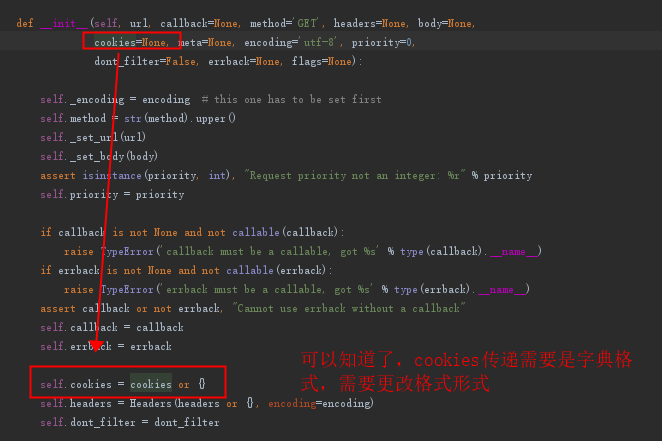
然后转成字典格式:
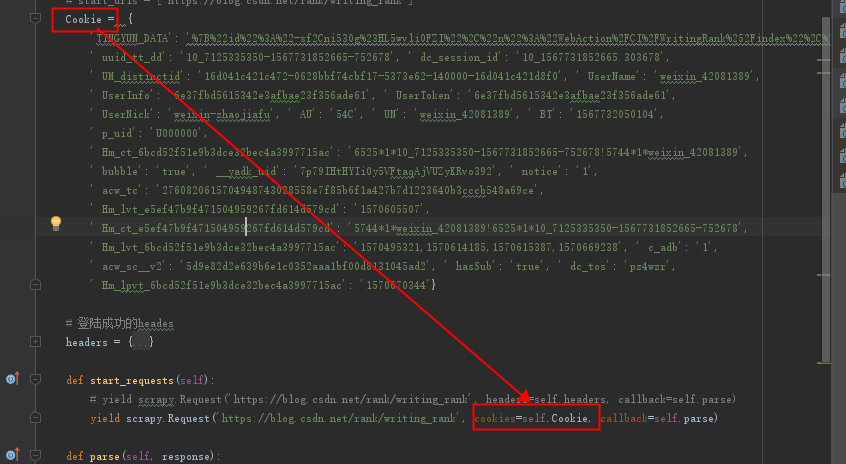
再次测试:
成功了。

7、搜索到添加cookie的三种方法:
然后我不甘心headers中,加入cookie不成功,肯定可以成功的,肯定哪个地方我没有设置好,requests模块都可以,这个应该也可以支持的。
然后我谷歌搜索到一个博客:
具体内容:
1 | 1.settings |
2 | settings文件中给Cookies_enabled=False解注释 |
3 | settings的headers配置的cookie就可以用了 |
4 | 这种方法最简单,同时cookie可以直接粘贴浏览器的。 |
5 | 后两种方法添加的cookie是字典格式的,需要用json反序列化一下, |
6 | 而且需要设置settings中的Cookies_enabled=True |
7 | |
8 | 2.DownloadMiddleware |
9 | settings中给downloadmiddleware解注释 |
10 | 去中间件文件中找downloadmiddleware这个类,修改process_request,添加request.cookies={}即可。 |
11 | |
12 | 3.爬虫主文件中重写start_request |
13 | |
14 | def start_requests(self): |
15 | yield scrapy.Request(url,dont_filter=True,cookies={自己的cookie}) |
发现,他的博客写的第3种方法就是我的刚刚成功的cookie字典格式的方法;
第1种方法就是需要在我的第一次headers尝试,需要setting中打开支持cookies就行了;
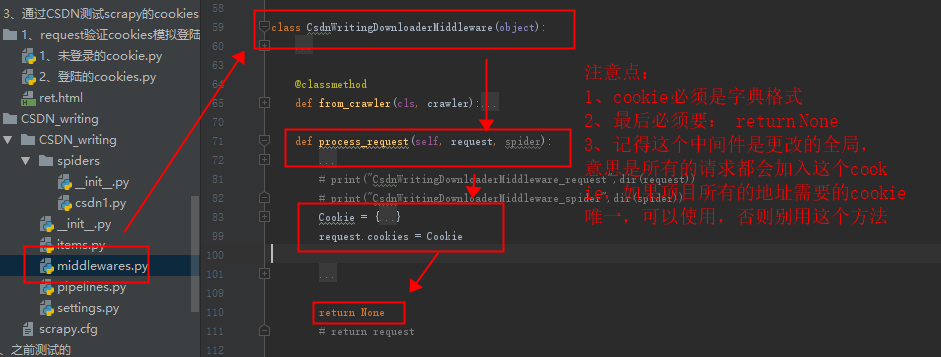
第2种方法需要进入下载中间件,修改downloadmiddleware中的process_request方法,在里面添加request.cookies={},记得是字典格式。
8、再次进行我的第一次方法尝试
通过分析,发现我的第一次不成功是因为setting中有个cookies设置需要打开,默认是关闭cookies,更改为:
1 | # Disable cookies (enabled by default) |
2 | COOKIES_ENABLED = False |
然后修改我的爬虫程序:
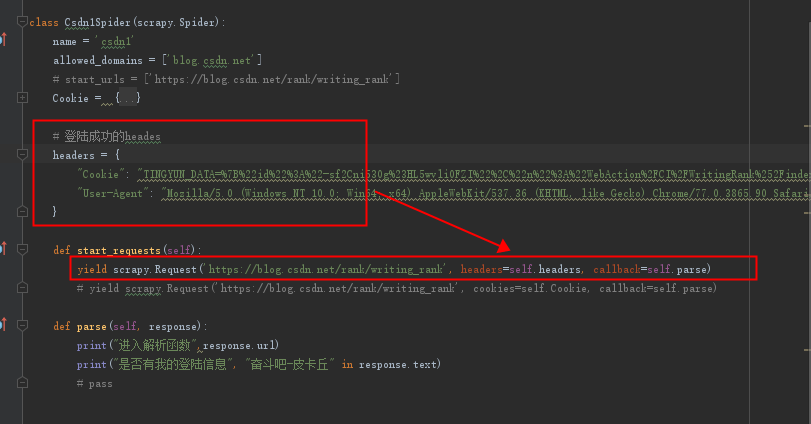
再次运行:成功!!!

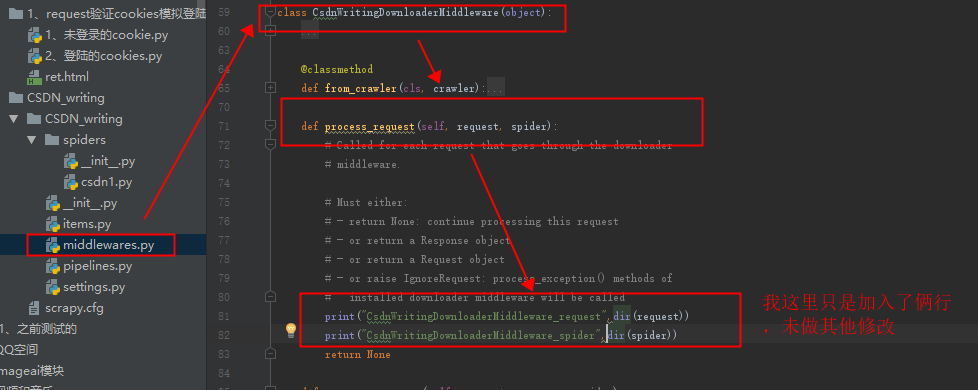
9、尝试通过下载中间件修改:
1、进入中间件:
2、修改setting设置
记得先在设置中打开,默认是关闭的:
发现有个文档,可以多研究研究这些文档:
https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
setting设置打开下载中间件:
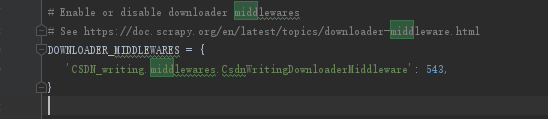
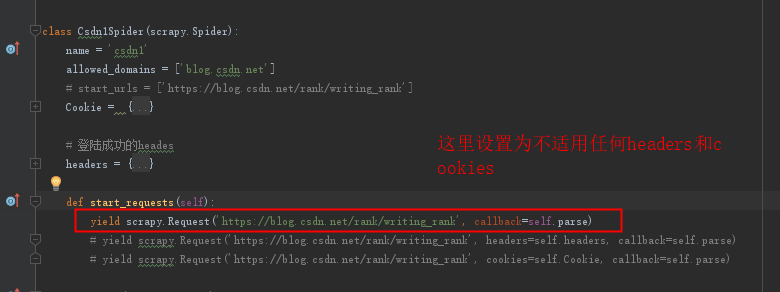
3、修改爬虫程序:
爬虫程序设置为不使用任何cookies。
4、测试打印:
通过打印出来的,我们可以看出,可以在下载中间件中加入cookei和headers,通过上面的文档可以了解到,如果setting中打开这个下载中间件,则scrapy框架发送每一个请求之前都会进入这个process_request方法中。

5、添加字典的cookie测试,看看效果(记得上面没加是False)
1. return None(这时候setting中cookie是打开着的,后来发现补充这一句)
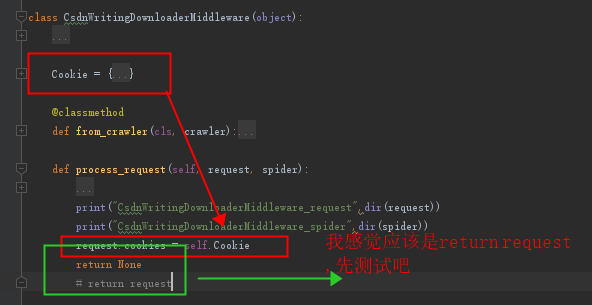

2. return request(这时候setting中cookie是打开着的,后来发现补充这一句)
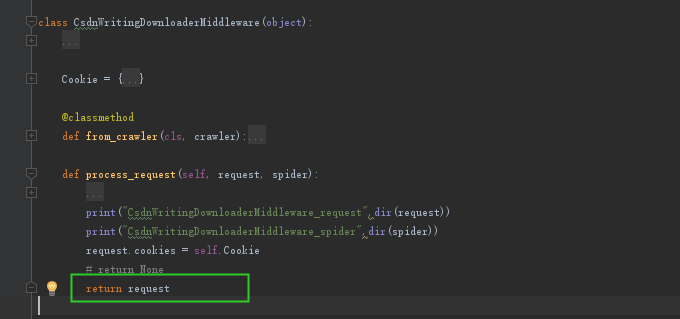
结果很令我惊讶,换成return request结果不进入解析函数了,很尴尬,找不到什么原因。

3、多次尝试之后,觉得是不是setting中的cookie打开和这个冲突的原因,然后开始摸索着尝试:
4、return None(关闭setting的cookie设置)
setting中设置:

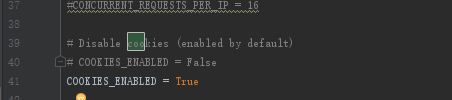
成功(return None+setting中关闭cookie,或者改为True):

4、return request(关闭setting的cookie设置)
这种无效,

5、我尝试了在中间件中国加入headers(好像确实不支持,只支持字典类型的cookies)
尝试了几次都不行。
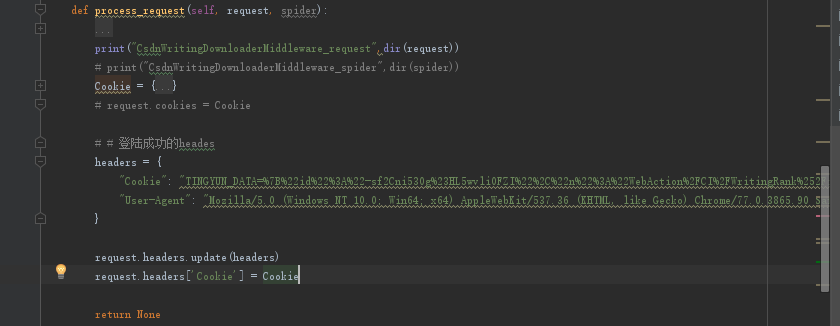
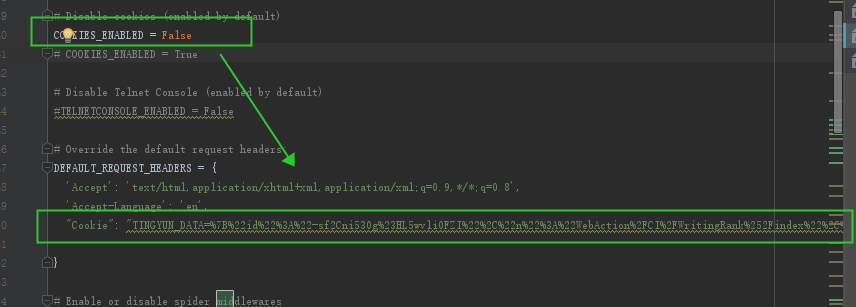
6、setting中加入默认的headers
- 打开setting中的cookie设置
- 添加cookie到setting中的默认的headers
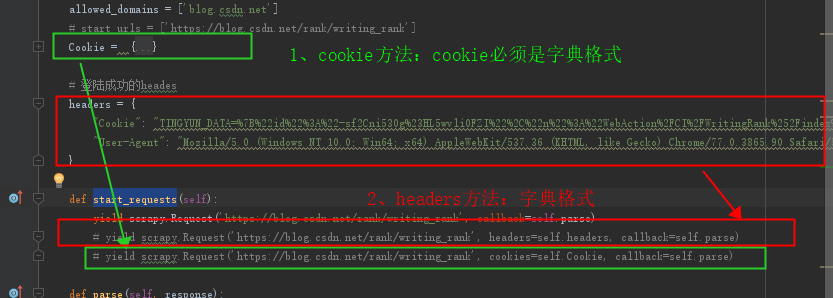
三、通过以为各种尝试:最终在scrapy中加入cookie,有以下3种方式:
1、在setting中将cookie设置打开(默认禁用的),然后再爬虫程序中重写start_requests方法
打开cookie设置:
1 | # Disable cookies (enabled by default) |
2 | COOKIES_ENABLED = False |
重新start_requests方法,然后可以使用添加cookie和headers方法,我比较喜欢headers方法,比较省事。
2、在setting中将cookie设置打开(默认禁用的),然后再修改setting中的默认headers,把cookies添加进去(推荐使用掌握这个方法。):
这个方法最简单,不要修改其他的。每种请求的地址可以自定义headers,可塑性比较强,最推荐使用掌握。
3、关闭setting的cookie设置(默认就是关闭,如果打开了,请关闭)– (不推荐使用)

总结:(最推荐使用第1个方法):
弄了一天总算测试完了,做个总结吧!!!
如果一个网站的所以cookie都是一样的,推荐使用第2种 方法,如果不一样,推荐使用第一个方法中的headers方法,因为你在解析函数中,还可能再发送 scrapy.Request请求和定义新的解析函数再请求scrapy.Request,这样如果需要不同的cookies或者不同的headers防止反反爬,在定义一个headers2就可以搞定(或者弄个cookies列表和user-agent列表,每次随意组合),不同类别的url,携带不同的url,而且如果对于有cookie反爬的网站,我还可以定义一个cookie列表,每次选择haders之前,先随机抽去一个cookies,组合成headers,这样能达到反反爬cookie(或者user-agent),如果是ip反爬,后续讨论,本章暂不讨论。
参考:
https://doc.scrapy.org/en/latest/topics/spiders.html

